
SQL Server表分區是提高數據庫性能和管理的寶貴特性,尤其是對大型表。其他主流的關系型數據庫也會有表分區的功能,通過將大型表劃分為更小、更易于管理的分區,有助于大型表管理。每個分區都可以存儲在單獨的文件組中,從而提高了查詢性能,簡化了備份和索引重建等維護任務。
1、定義配分函數
分區函數指示如何將表中的行映射到不同的分區。分區函數和表的分區列必須具有相同的數據類型。
-- 刪除分區函數IF EXISTS (SELECT * FROM sys.partition_functions WHERE name = 'PFYear')BEGIN DROP PARTITION FUNCTION PFYear;ENDGO-- 創建分區函數CREATE PARTITION FUNCTION PFYear (date)AS RANGE RIGHT FOR VALUES ('2021-01-01', '2022-01-01', '2023-01-01', '2024-01-01');GO
2、創建分區方案
分區方案將分區映射到特定的文件組。文件組及文件需提前創建好。
-- 刪除分區方案IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name = 'PSYear')BEGIN DROP PARTITION SCHEME PSYear;ENDGO-- 創建分區方案(提前創建文件組及文件)CREATE PARTITION SCHEME PSYear AS PARTITION PFYearTO (FG2021, FG2022, FG2023, FG2024, [PRIMARY]);GO
3、創建分區表
在創建分區表時,請確保所有唯一索引或主鍵都包含分區列,以符合SQL Server的要求。
CREATE TABLE Sales ( SaleID int IDENTITY(1,1), SaleDate date, TotalAmount money, CustomerID int, ProductID int, Quantity int, PRIMARY KEY (SaleDate, SaleID)) ON PSYear (SaleDate);GO
該結構使用SaleDate作為主鍵的一部分,并將其與分區列對齊。
插入數據
以下測試按不同年份插入數據,數據將自動分布在不同分區上:
INSERT INTO Sales (SaleDate, TotalAmount, CustomerID, ProductID, Quantity)VALUES ('2018-03-15', 120.50, 1, 101, 2), ('2019-07-22', 75.00, 2, 102, 1), ('2020-05-11', 200.00, 3, 103, 5), ('2021-12-01', 150.00, 4, 104, 3);
查詢分區數據
要查看跨分區的數據分布,可以運行:
SELECT $PARTITION.YearPartitionFunction(SaleDate) AS PartitionNumber, COUNT(*) AS RecordsFROM SalesGROUP BY $PARTITION.YearPartitionFunction(SaleDate);GO
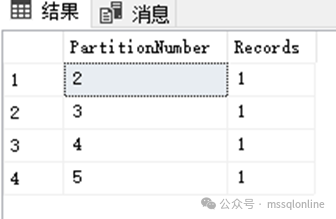
對分區表進行有針對性的維護可以減少停機時間并優化數據庫性能。
索引維護
可以在每個分區的基礎上重建或重新組織索引,重點關注數據修改頻繁的區域。下面命令表示在第三個分區上重建索引。
-- SP_HELP SalesALTER INDEX IX_SaleDate ON Sales REBUILD PARTITION = 3;GO
統計數據更新
保持特定分區的統計信息更新有助于SQL Server查詢優化器做出明智的決策,從而提高性能。下面更新第三個分區的統計信息。
UPDATE STATISTICS Sales (IX_SaleDate) WITH RESAMPLE ON PARTITIONS(3);GO
高效的數據管理
SQL Server的分區允許通過分區輕松歸檔或刪除數據。
ALTER TABLE Sales SWITCH PARTITION 10 TO Archive.Sales PARTITION 10;GO
性能考慮
我們有2張日志表 Logs 與 IPRequests 插入數據較頻繁。兩表沒有業務需求,日常偶爾用于查看系統錯誤信息,給開發同事排錯用。我們對兩表 Logs 與 IPRequests 都創建了分區,保留10天數據,10天前的數據分別遷移到另一個中間表 LogsMid 與 IPRequestsMid。中間表不用分區,但結構和索引要和原來的表一樣。數據遷移到中間表后,中間表會再將數據遷移到另一個歸檔數據庫 T_TempDB 的表 dbo.T_Logs_history 與 dbo.T_IPRequests_history。而表 T_Logs_history 和 T_IPRequests_history 只保留30天數據!
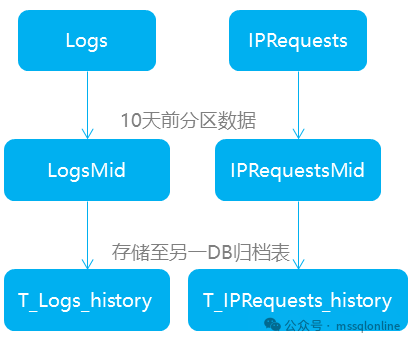
對于分區表的設置,允許鎖升級到分區鎖,不用升級到表鎖。
ALTER TABLE [dbo].[Logs] SET (LOCK_ESCALATION=AUTO)GOALTER TABLE [dbo].[IPRequests] SET (LOCK_ESCALATION=AUTO)GO
更多參考:SQL Server 表選項 LOCK_ESCALATION 對分區的影響
以上各步驟的操作過程,是通過作業自動執行的,分區切換很快。作業分為以下步驟:
declare @now date;declare @next_day nvarchar(10);declare @prio_day datetime;declare @next_fg nvarchar(50);declare @sql nvarchar(500);set @now = getdate()set @next_day = convert(varchar(10),@now,120) set @prio_day = dateadd(d,-10,@now) set @next_fg = N'filegroup_'+convert(nvarchar(10),datediff(D,'2020-01-01',@now)%10+1)
SET @sql = N'ALTER PARTITION SCHEME PS_DateTime NEXT USED ' + @next_fg + '; 'set @sql = @sql + N'ALTER PARTITION FUNCTION PF_DateTime() SPLIT RANGE(''' + @next_day + ''');'exec(@sql);
ALTER TABLE Logs SWITCH PARTITION 1 TO LogsMidALTER TABLE IPRequests SWITCH PARTITION 1 TO IPRequestsMid
ALTER PARTITION FUNCTION PF_DateTime() MERGE RANGE(@prio_day);
insert into T_TempDB.dbo.T_Logs_history select * from dbo.LogsMid;GOinsert into T_TempDB.dbo.T_IPRequests_history select * from dbo.IPRequestsMid;GO
truncate table dbo.LogsMid;GOtruncate table dbo.IPRequestsMid;GO
update statistics dbo.Logs;GOupdate statistics dbo.IPRequests;GO
DELETE FROM T_TempDB.dbo.T_Logs_history WHERE OperationTime <= DATEADD(M,-1,GETDATE())GODELETE FROM T_TempDB.dbo.T_IPRequests_history WHERE AddTime <= DATEADD(M,-1,GETDATE())GO
通過分區及分區維護,我們查詢數據性能大大提高了。
? 總結 ?
SQL Server表分區可以顯著提高大型數據庫的性能、管理性和可擴展性。同樣也可以簡化備份與恢復。
對于日志表的考慮,如果是比較重要的業務操作日志,個人建議最好單獨使用一個數據庫。我們知道操作日志非常頻繁,數據量也會非常大,但又不是那么重要。單獨日志庫會大大減少業務庫的大小,這樣對業務庫的備份恢復、數據同步、參數設置等都有非常好的性能。如果操作日志沒那么重要,可以不必存儲在關系型數據庫中,非關系型數據庫有較好的擴展性、壓縮性、高效搜索、多數據模型等。
閱讀原文:原文鏈接
該文章在 2025/1/10 11:11:10 編輯過






 400 186 1886
400 186 1886


