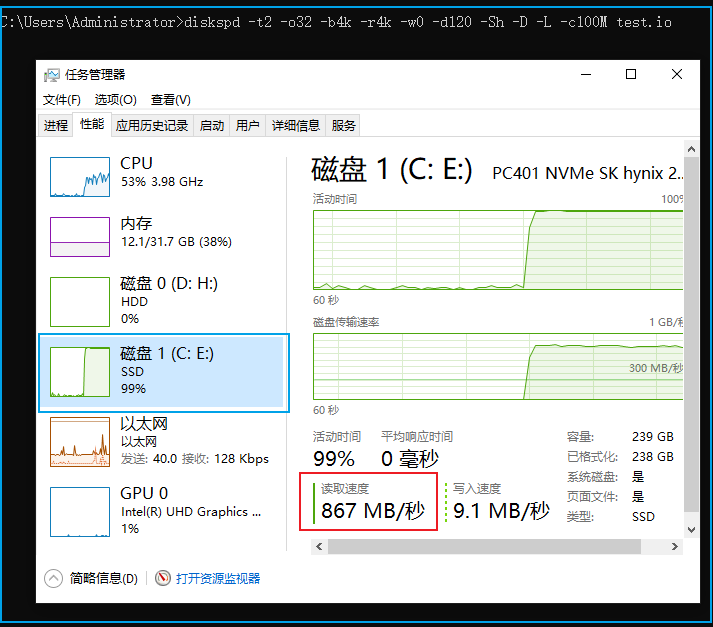
經常逛微軟的 Github 倉庫會發現很多好東西,比如這次介紹的 diskspd 命令行工具。diskspd 是一款磁盤性能測試工具,Github 項目地址為:使用 diskspd 可以輕松將磁盤的性能跑滿,從而測試磁盤的吞吐量、IOPS和延遲。對于很多虛擬機、網絡文件系統,比如 NAS 、iSCSI,它們并非真實的硬件。使用硬盤測速、SSD測速等硬件測速工具無法對其進行有效的測試。diskspd 可以通過讀寫文件的形式來測試真實系統的IO性能。diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c100M test.io
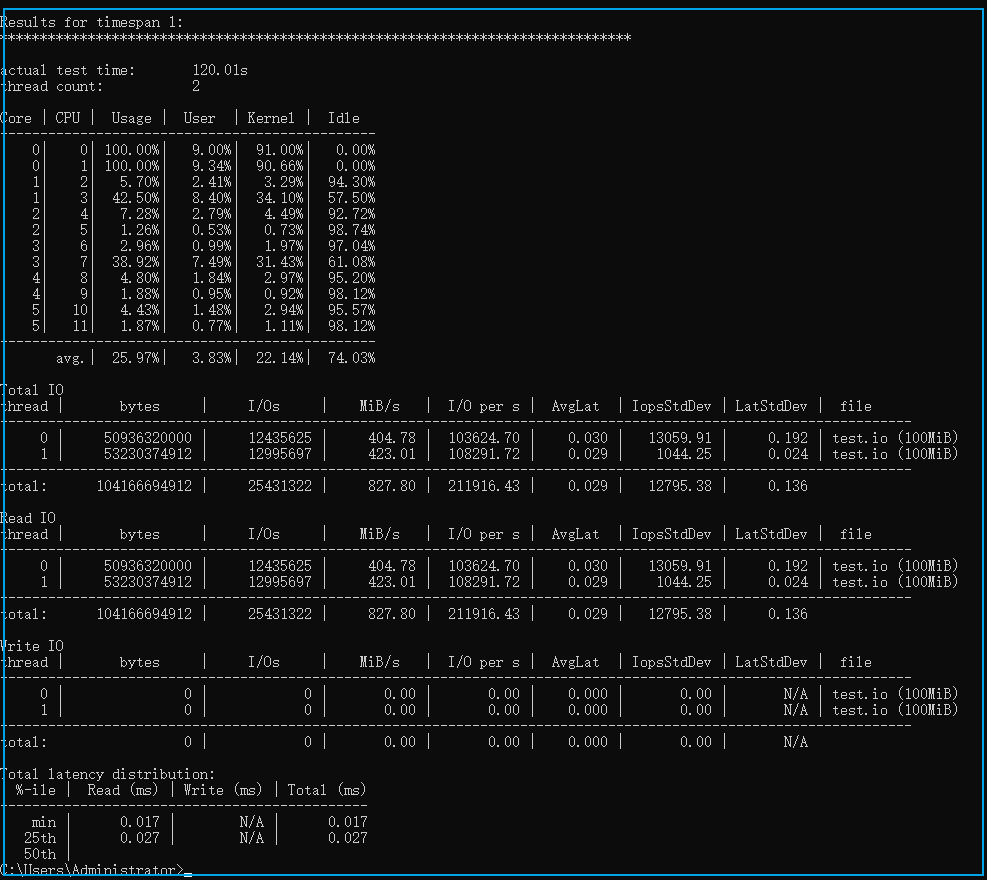
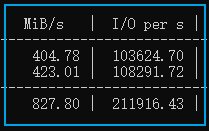
以上例子對 C 盤下的 test.io 文件進行測試,起了兩個測試線程,文件大小為 100M ,測試時間為 120s,最終測試報告如下:兩個線程,每個IO吞吐量為400MB/s,一共800MB/s,IOPS為 200000,延遲為 0.027 msdiskspd 的參數比較多,通過 diskspd /? 可以查看幫助文檔。以上例子中用的的參數有:-t2:這表示每個目標/測試文件的線程數。此數字通常基于 CPU 核心數。在本例中,使用兩個線程來對所有 CPU 核心施加壓力。-o32:這表示每個目標每個線程的未完成 I/O 請求數。這也稱為隊列深度,在本例中,使用 32 來強調 CPU。-b4K:這表示塊大小(以字節、KiB、MiB 或 GiB 為單位)。在本例中,使用 4K 塊大小來模擬隨機 I/O 測試。-r4K:這表示隨機 I/O 與指定大小(以字節、KiB、MiB、Gib 或塊為單位)對齊(覆蓋-s參數)。使用常見的 4K 字節大小與塊大小正確對齊。-w0:指定寫入請求操作的百分比(-w0 相當于 100% 讀取)。在本例中,0% 寫入用于進行簡單測試。-d120:這指定了測試的持續時間,不包括冷卻或預熱時間。默認值為 10 秒,但我們建議對于任何嚴重的工作負載至少使用 60 秒。在本例中,使用了 120 秒來盡量減少任何異常值。-Suw:禁用軟件和硬件寫入緩存(相當于-Sh)。-D:以毫秒為間隔捕獲 IOPS 統計數據,例如標準偏差(每個線程、每個目標)。-L:測量延遲統計數據。-c100M:設置測試中使用的樣本文件大小。可以以字節、KiB、MiB、GiB 或塊為單位進行設置。在本例中,使用了 100M 的目標文件。
Examples:
Create 8192KB file and run read test on it for 1 second:------------------------------------創建一個8192KB的文件,并對其運行1秒的read test:
diskspd -c8192K -d1 testfile.dat
Set block size to 4KB, create 2 threads per file, 32 overlapped (outstanding)I/O operations per thread, disable all caching mechanisms and run block-aligned randomaccess read test lasting 10 seconds:-------------------------------------------將塊大小設置為4KB,每個文件創建2個線程,每個線程32個重疊I/O操作,禁用所有緩存機制并運行塊對齊隨機訪問讀取測試,持續10秒:
diskspd -b4K -t2 -r -o32 -d10 -Sh testfile.dat
Create two 1GB files, set block size to 4KB, create 2 threads per file, affinitize threadsto CPUs 0 and 1 (each file will have threads affinitized to both CPUs) and run read testlasting 10 seconds:-----------------------------創建兩個1GB的文件,將塊大小設置為4KB,為每個文件創建2個線程,將線程關聯到cpu 0和1(每個文件將有線程關聯到兩個cpu),并運行持續10秒的read測試:
diskspd -c1G -b4K -t2 -d10 -a0,1 testfile1.dat testfile2.dat
“吞吐量”是一個比較容易理解的性能參數,與我們平時拷貝文件時看到的拷貝速度是一個意思。吞吐量越大代表拷貝大文件時的速度越快。與“吞吐量”相對應的是,IOPS代表對小文件的操作性能。IOPS是個頻率,IOPS越高代表“手數”越快,也就是短時間內可操作的文件數越多。在處理海量小文件時,光統計文件數量這個操作對IOPS的要求就比較高。延遲代表著多任務排隊時需要等待。一般實時程序、數據庫對IO延遲比較敏感。并且 IOPS 越高并不代表著延遲越低,相反當IOPS提高時,延遲可能會增加。IOPS用于衡量存儲設備能處理的I/O請求的頻率,而延遲衡量每個I/O請求的響應速度。高IOPS并不一定意味著低延遲,反之亦然。高并發操作可能導致更高的延遲。選擇存儲時,需要考慮使用場景,確定是更需要高IOPS(例如海量小文件操作),還是低延遲(例如數據庫查詢或實時處理)。
閱讀原文:原文鏈接
該文章在 2024/12/30 14:36:45 編輯過






 400 186 1886
400 186 1886