spark最近出了2.0版本,其安裝和使用也發生了些許的變化。筆者的環境為:centos7.
該文章主要是講述了在centos7上搭建spark2.0的具體操作和spark的簡單使用,希望可以給剛剛接觸spark的朋友一些幫助。
按照慣例,文章的最后列出了一些參考文獻,以示感謝。下面我們就來看一下spark的安裝。
spark的依賴環境比較多,需要Java JDK、hadoop的支持。我們就分步驟依次介紹各個依賴的安裝和配置。spark2.0運行在Java 7+, Python 2.6+/3.4+ , R3.1+平臺下,如果是使用scala語言,需要 Scala2.11.x版本,hadoop最好安裝2.6以上版本。 由于spark本身是用scala實現的,所以建議使用scala,本文中的示例也大多是scala語言。當然spark也可以很好地支持java\python\R語言。
spark的使用有這么幾類:spark shell交互,spark SQL和DataFrames,spark streaming, 獨立應用程序。
注意,spark的使用部分,不特殊說明,都是以hadoop用戶登錄操作的。
1.安裝Java環境
我的centos7安裝系統的時候選擇了安裝openJDK的環境,所以可以直接使用。但這里還是列出jdk的安裝步驟供大家參考。java環境可以使用Oracle的jdk或者openjdk. 下面的步驟是openjdk的安裝示范。
a.首先檢查是否安裝了jdk, 和版本是否符合要求。
java -version
若安裝了java環境,但是版本太低,則先卸載原版本,再安裝新版本。
卸載可參考以下步驟
yum -y remove java-1.7.0-openjdk*
yum -y remove tzdata-java.noarch
b.若未安裝或已卸載,安裝新版本
查看可用版本
yum -y list java*
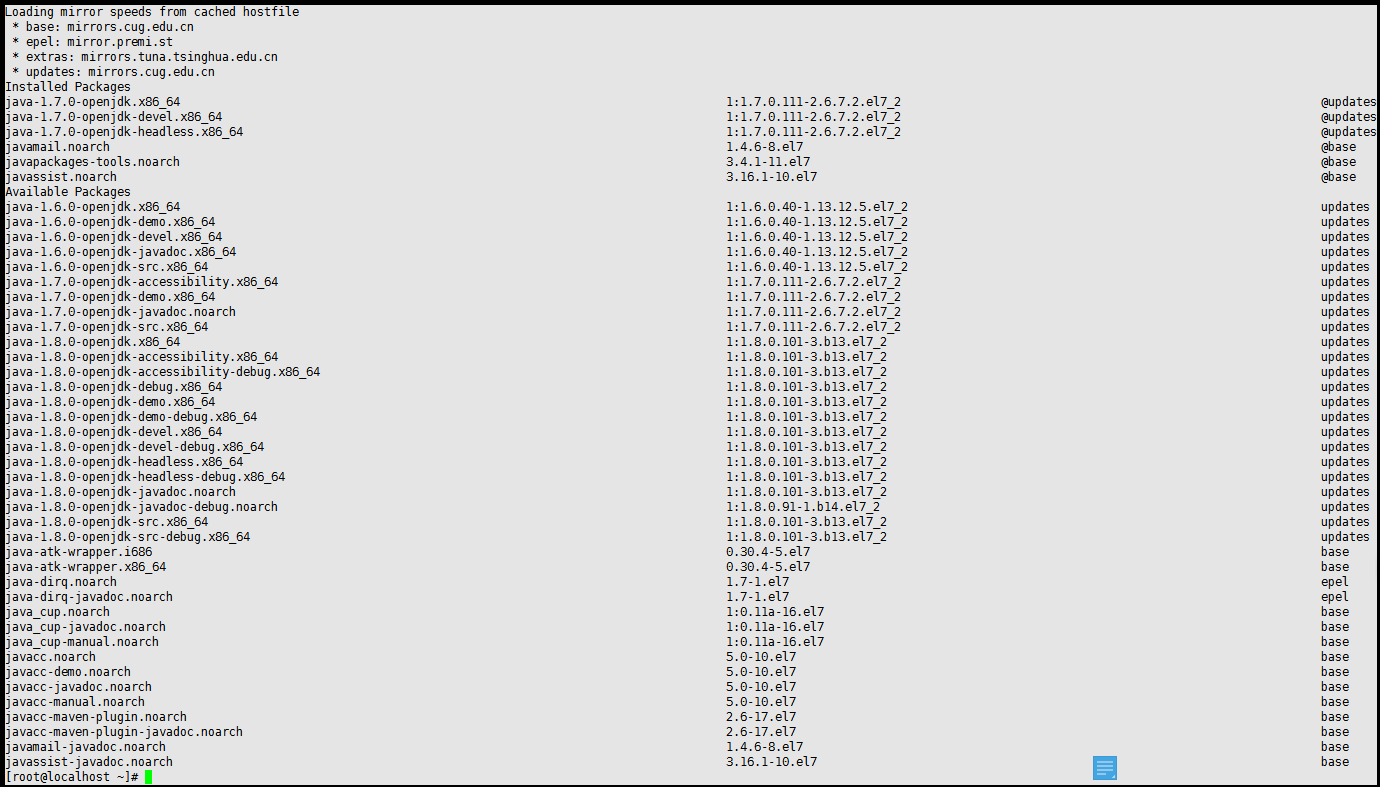
以安裝1.7版本為例
yum -y install java-1.7.0-openjdk*
c.配置環境變量
vi /etc/profile
在文件的最后添加
JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk
PATH=$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
其中JAVA_HOME是你的java安裝路徑。其中PATH這個參數是以冒號:來分割不同的項的,后面我們hadoop和spark的環境變量配置也要修改這個參數。
保存退出后,還需要執行
source /etc/profile
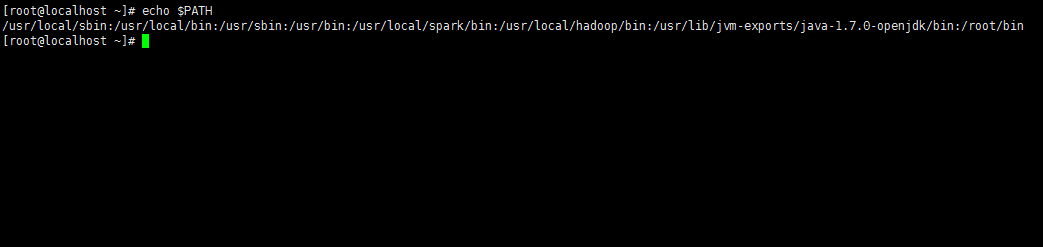
該文件才可以生效。檢查環境變量是否配置生效
echo $PATH
2.安裝hadoop
如果你安裝 CentOS 的時候不是用的 “hadoop” 用戶,那么需要增加一個名為 hadoop 的用戶。
a.以root身份登錄,添加”hadoop”用戶
useradd -m hadoop -s /bin/bash
密碼輸入兩次,筆者使用”hadoop”作為密碼,比較好記憶。這樣,一個用戶名為hadoop, 密碼也是hadoop的用戶就添加好了。
b.可為 hadoop 用戶增加管理員權限,方便部署,避免一些對新手來說比較棘手的權限問題
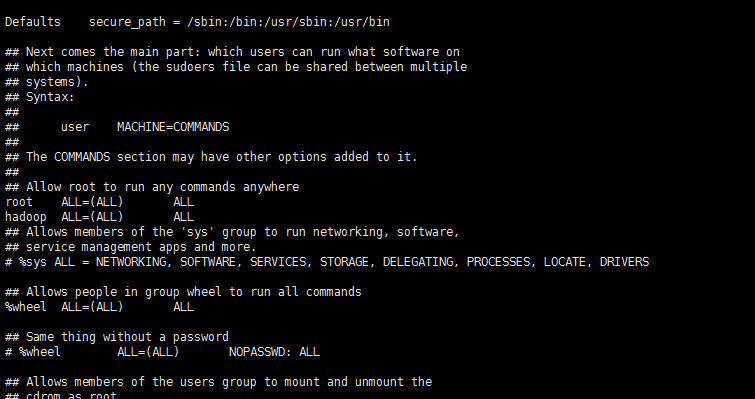
visudo
找到 root ALL=(ALL) ALL 這行(應該在第98行,可以先按一下鍵盤上的 ESC 鍵,然后輸入 :98 (按一下冒號,接著輸入98,再按回車鍵),可以直接跳到第98行 ),然后在這行下面增加一行內容:hadoop ALL=(ALL) ALL (當中的間隔為tab),如下圖所示:
c.centos默認安裝ssh. 如果你的操作系統中沒有ssh, 可以自行安裝,最后的參考資料中有ssh的安裝和配置。
d.安裝hadoop
去官網下載hadoop的安裝包,下載時請下載 hadoop-2.x.y.tar.gz 這個格式的文件,這是編譯好的,另一個包含 src 的則是 Hadoop 源代碼,需要進行編譯才可使用。
下載時強烈建議也下載 hadoop-2.x.y.tar.gz.mds 這個文件,該文件包含了檢驗值可用于檢查 hadoop-2.x.y.tar.gz 的完整性,否則若文件發生了損壞或下載不完整,Hadoop 將無法正常運行。
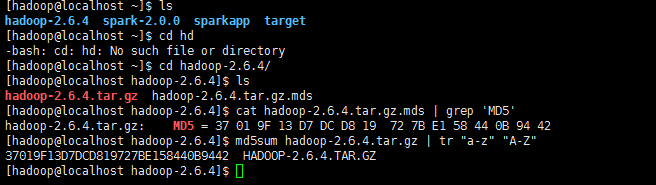
校驗一下下載文件是否完整
cat hadoop-2.6.4.tar.gz.mds | grep 'MD5'
md5sum hadoop-2.6.4.tar.gz | tr "a-z" "A-Z"
我們選擇將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop
sudo chown -R hadoop:hadoop ./hadoop
Hadoop 解壓后即可使用。輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
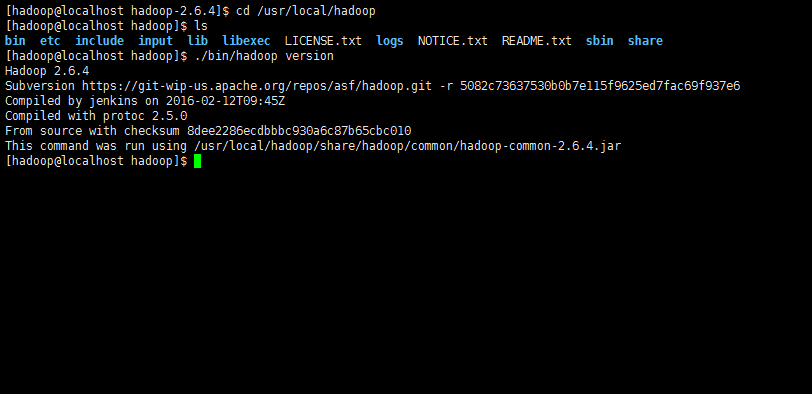
Hadoop 默認模式為非分布式模式,無需進行其他配置即可運行。非分布式即單 Java 進程,方便進行調試。
現在我們可以執行例子來感受下 Hadoop 的運行。Hadoop 附帶了豐富的例子(運行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
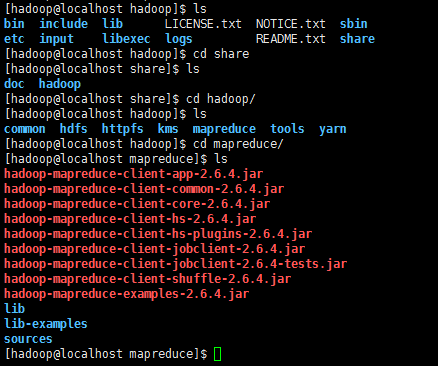
在此我們選擇運行 grep 例子,我們將 input 文件夾中的所有文件作為輸入,篩選當中符合正則表達式 dfs[a-z.]+ 的單詞并統計出現的次數,最后輸出結果到 output 文件夾中
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/*
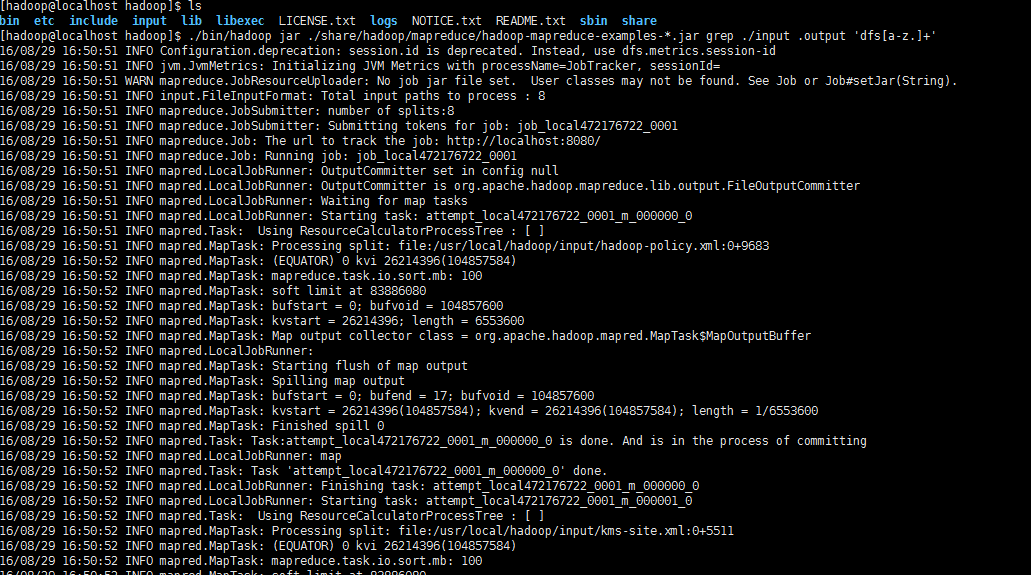
執行信息會很多,最后結果如下圖所示:
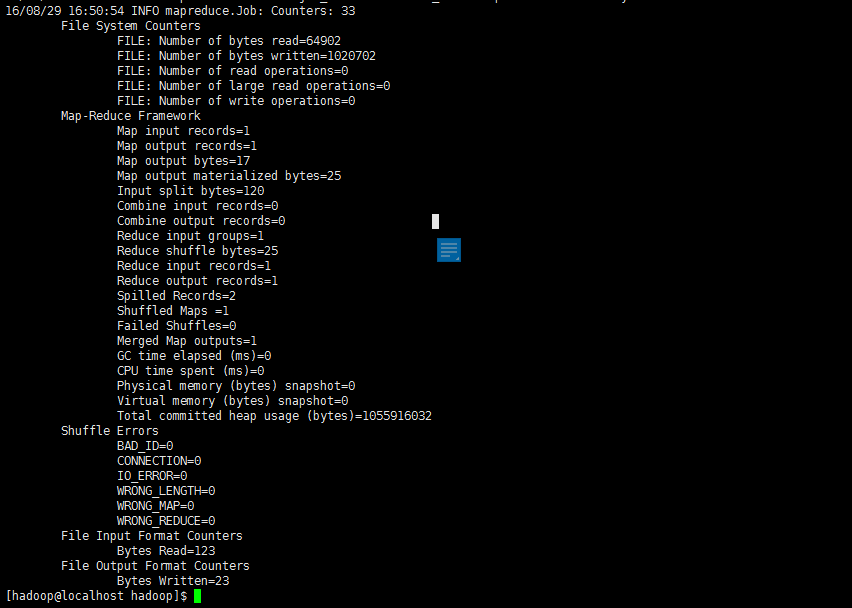
注意,Hadoop 默認不會覆蓋結果文件,因此再次運行上面實例會提示出錯,需要先將 ./output 刪除。
3.spark的安裝
a.先到官網下載安裝包
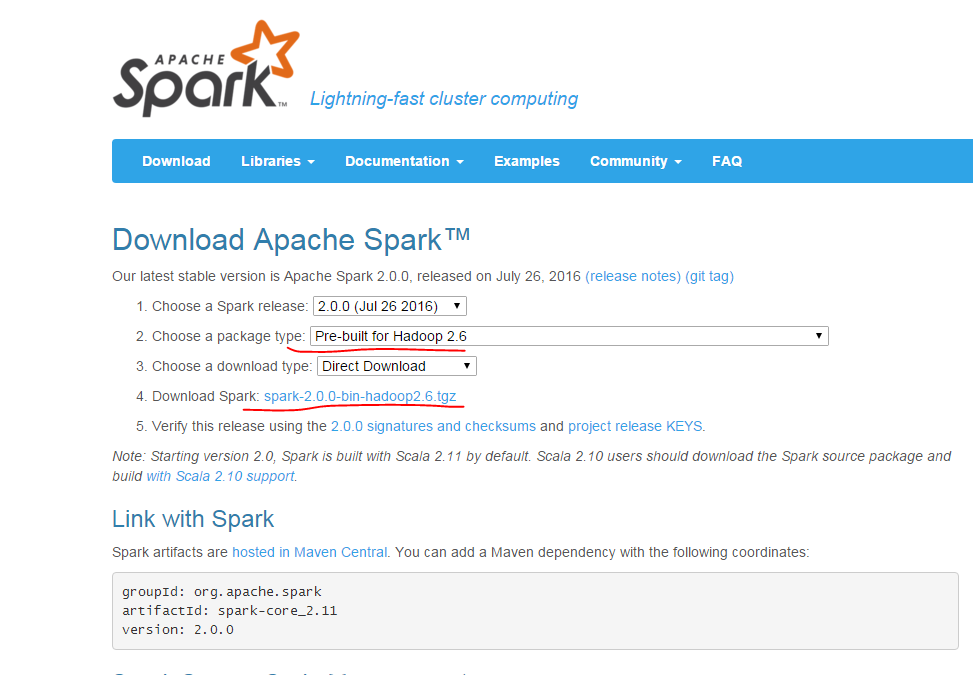
注意第二項要選擇和自己hadoop版本相匹配的spark版本,然后在第4項點擊下載。若無圖形界面,可用windows系統下載完成后傳送到centos中。
b.安裝spark
sudo tar -zxf ~/spark-2.0.0/spark-2.0.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-1.6.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark
c.配置spark
安裝后,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,執行如下命令拷貝一個配置文件:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
編輯 ./conf/spark-env.sh(vim ./conf/spark-env.sh) ,在最后面加上如下一行:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
保存后,Spark 就可以啟動了。
4.spark的簡單使用
在 ./examples/src/main 目錄下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等語言的版本。我們可以先運行一個示例程序 SparkPi(即計算 π 的近似值),執行如下命令:
cd /usr/local/spark
./bin/run-example SparkPi
執行時會輸出非常多的運行信息,輸出結果不容易找到,可以通過 grep 命令進行過濾(命令中的 2>&1 可以將所有的信息都輸出到 stdout 中,否則由于輸出日志的性質,還是會輸出到屏幕中):
cd /usr/local/spark
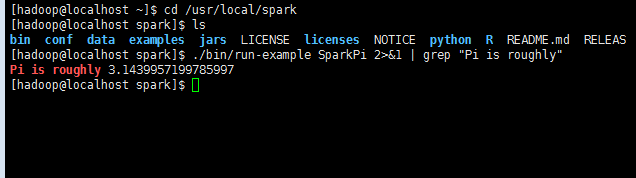
./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
過濾后的運行結果如下圖所示,可以得到 π 的 近似值 :
如果是Python 版本的 SparkPi, 則需要通過 spark-submit 運行:
./bin/spark-submit examples/src/main/python/pi.py
5.spark的交互模式
a.啟動spark shell
Spark shell 提供了簡單的方式來學習 API,也提供了交互的方式來分析數據。Spark Shell 支持 Scala 和 Python,本文中選擇使用 Scala 來進行介紹。
Scala 是一門現代的多范式編程語言,志在以簡練、優雅及類型安全的方式來表達常用編程模式。它平滑地集成了面向對象和函數語言的特性。Scala 運行于 Java 平臺(JVM,Java 虛擬機),并兼容現有的 Java 程序。
Scala 是 Spark 的主要編程語言,如果僅僅是寫 Spark 應用,并非一定要用 Scala,用 Java、Python 都是可以的。使用 Scala 的優勢是開發效率更高,代碼更精簡,并且可以通過 Spark Shell 進行交互式實時查詢,方便排查問題。
cd /usr/local/spark
./bin/spark-shell
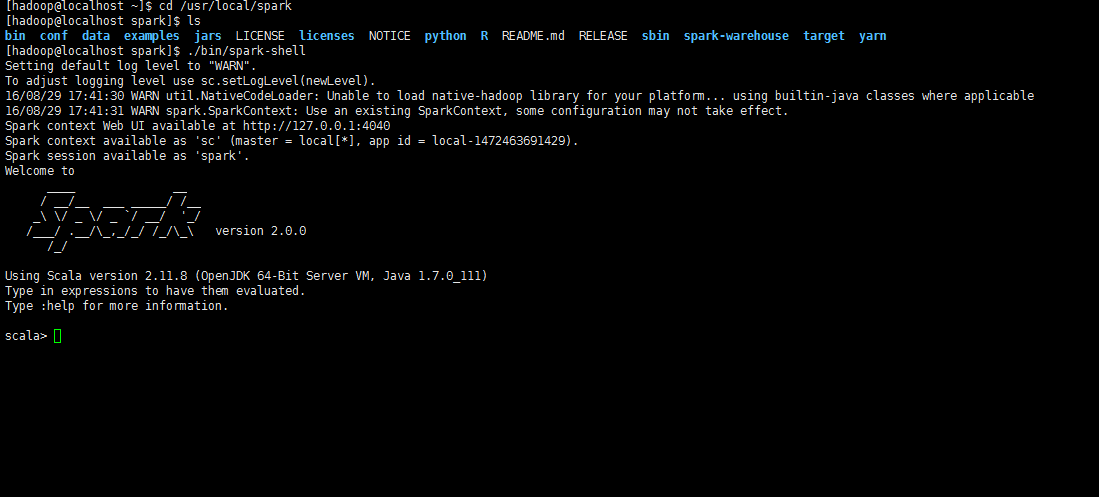
b.spark shell使用小例子
Spark 的主要抽象是分布式的元素集合(distributed collection of items),稱為RDD(Resilient Distributed Dataset,彈性分布式數據集),它可被分發到集群各個節點上,進行并行操作。RDDs 可以通過 Hadoop InputFormats 創建(如 HDFS),或者從其他 RDDs 轉化而來。
我們從 ./README 文件新建一個 RDD,代碼如下(本文出現的 Spark 交互式命令代碼中,與位于同一行的注釋內容為該命令的說明,命令之后的注釋內容表示交互式輸出結果):
val textFile = sc.textFile("file:///usr/local/spark/README.md")
代碼中通過 “file://” 前綴指定讀取本地文件。Spark shell 默認是讀取 HDFS 中的文件,需要先上傳文件到 HDFS 中,否則會報錯。
RDDs 支持兩種類型的操作
actions: 在數據集上運行計算后返回值
transformations: 轉換, 從現有數據集創建一個新的數據集
下面我們就來演示 count() 和 first() 操作:
textFile.count()
textFile.first()
接著演示 transformation,通過 filter transformation 來返回一個新的 RDD,代碼如下:
val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark.count()
action 和 transformation 可以用鏈式操作的方式結合使用,使代碼更為簡潔:
textFile.filter(line => line.contains("Spark")).count()
6.spark執行獨立程序
a.配置spark和hadoop環境變量
cd ~
vi /etc/profile
找到PATH參數,在最后添加spark和hadoop的環境變量,具體到bin即可。注意每條之間使用冒號隔開。如下圖
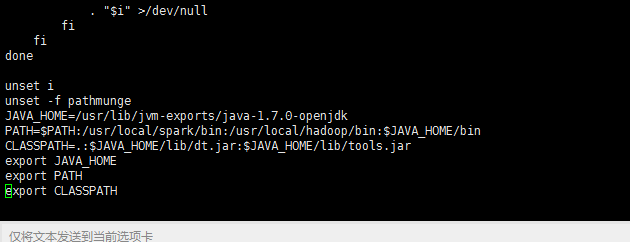
修改完成,保存退出,執行
source /ect/profile
文件生效。同樣可以使用echo $PATH 來查看環境變量是否添加成功。
b.安裝sbt
SBT(Simple Build Tool)即簡單構造工具,它是用scala寫的,具有強大的依賴管理功能,所有任務的創建都支持Scala,可連續執行命令。可以在工程的上下文里啟動REPL。
一般來說,使用 Scala 編寫的程序需要使用 sbt 進行編譯打包,相應的,Java 程序使用 Maven 編譯打包,而 Python 程序通過 spark-submit 直接提交。但是scala也可以使用maven來打包,不過配置起來較為復雜。這里就不再贅述了。
到官網下載安裝包(http://www.scala-sbt.org/)。安裝到/usr/local/sbt文件夾中
sudo mkdir /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt
cd /usr/local/sbt
接著在 /usr/local/sbt 中創建 sbt 腳本(vim ./sbt),添加如下內容:
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
注意這里的最后一行的 dirname 0,它是被倒引號括起來的,不是單引號。被倒引號括起來的東西表示要執行的命令。dirname0,它是被倒引號括起來的,不是單引號。被倒引號括起來的東西表示要執行的命令。dirname0 只能用在腳本中,在命令行中是無效的,它的意思是去當前腳本所在位置的路徑。
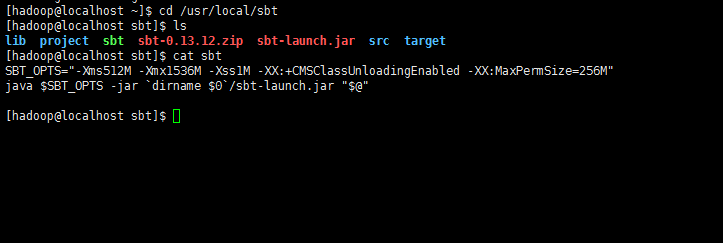
很明顯。這里你要檢查/usr/local/sbt 夾下sbt-launch.jar這個文件是否存在。因為筆者和網上眾多教程都提到了,因為網絡的原因,sbt下載的時候,這個依賴包有可能缺失。如果沒有,請自行下載(http://pan.baidu.com/s/1gfHO7Ub)
c.構建scala工程目錄
sbt打包scala是有固定工程目錄結構的。
cd ~
mkdir ./sparkapp
mkdir -p ./sparkapp/src/main/scala
d.編寫獨立程序
這里我們借用官網上的一個小的demo.
cd ~
cd sparkapp/src/main/scala
vi SimpleApp.scala
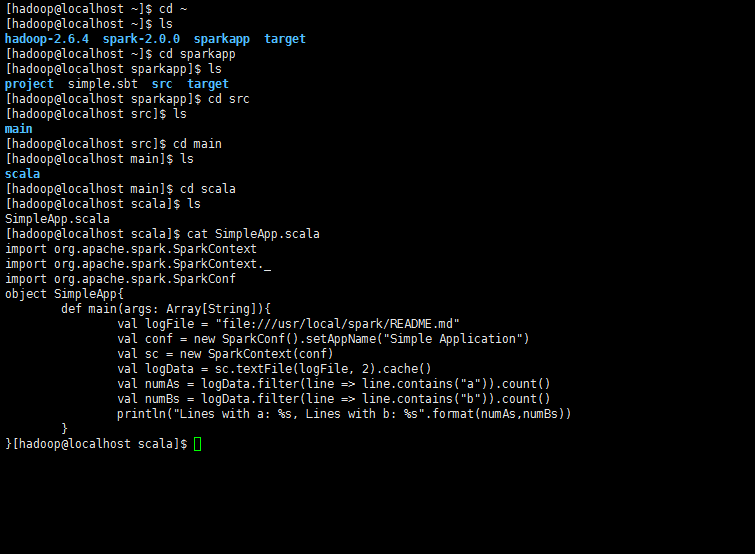
文件內容為程序主體
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
e.添加配置文件
cd ~
cd sparkapp/
vi simple.bat
文件添加下面內容
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.0"
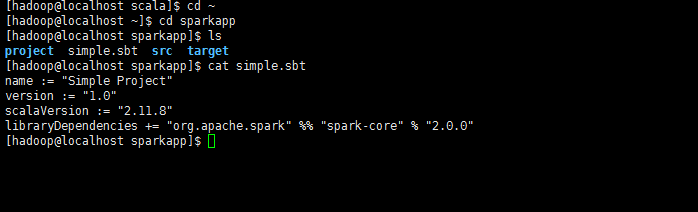
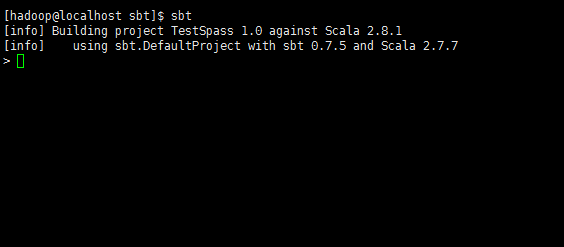
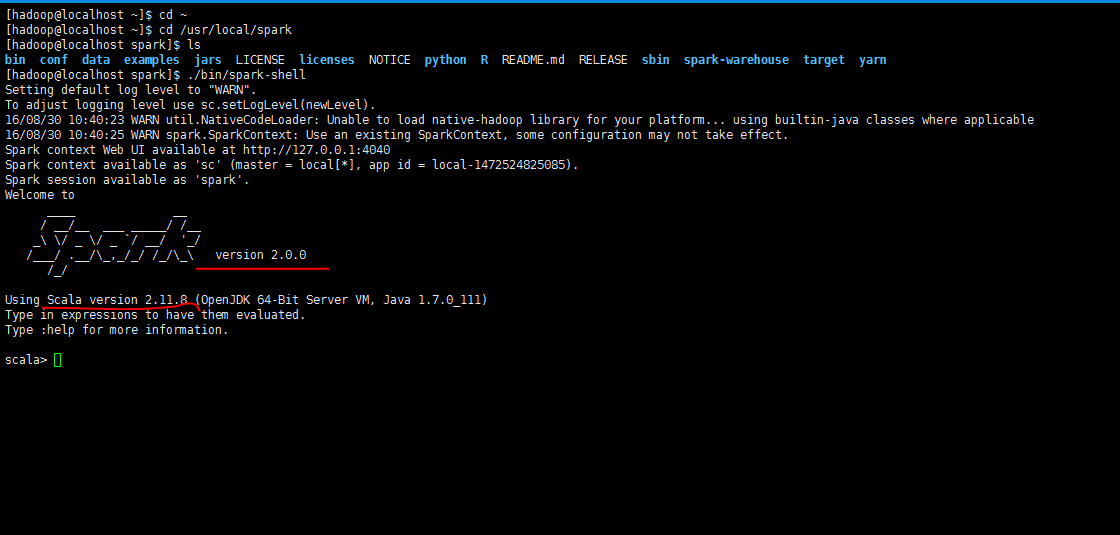
*注意,這里的scalaVersion和spark-core后面的版本號都要換成你自己的。
這兩個版本號,在啟動spark的時候有顯示。如下圖*
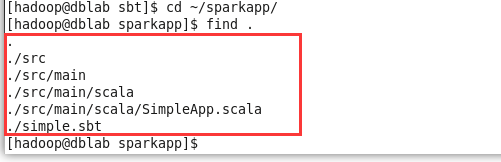
至此為止,檢查一下工程目錄結構
cd ~
cd sparkapp
find .
f.使用sbt打包scala程序
cd ~
cd sparkapp/
sbt package
第一次打包時間很長,需要下載各種依賴包,所以請耐心等待。生成的jar包位置在~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
g.提交編譯后的程序
cd ~
cd /usr/local/spark
./bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
輸出信息較多,可使用grep過濾結果
.bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"

到此為止,本文就結束了,關于文章中沒有介紹的spark SQL和DataFrames,大家有興趣的可以到下面列出的參考文獻中查找。
按照慣例,列出參考文獻供大家參考:
1.http://spark.apache.org/docs/latest/building-spark.html
2.http://spark.apache.org/docs/latest/quick-start.html
3.http://spark.apache.org/docs/latest/programming-guide.html
4.http://www.importnew.com/4311.html
5.http://www.scala-sbt.org/
6.http://blog.csdn.net/czmchen/article/details/41047187
7.http://blog.csdn.net/zwhfyy/article/details/8349788
8.http://jingyan.baidu.com/article/948f59242c231fd80ff5f9ec.html
9.http://dblab.xmu.edu.cn/blog/install-hadoop/
10.http://dblab.xmu.edu.cn/blog/spark-quick-start-guide/
11.http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
該文章在 2024/12/11 9:50:19 編輯過






 400 186 1886
400 186 1886


