使用Tesseract進(jìn)行圖片文字識(shí)別
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
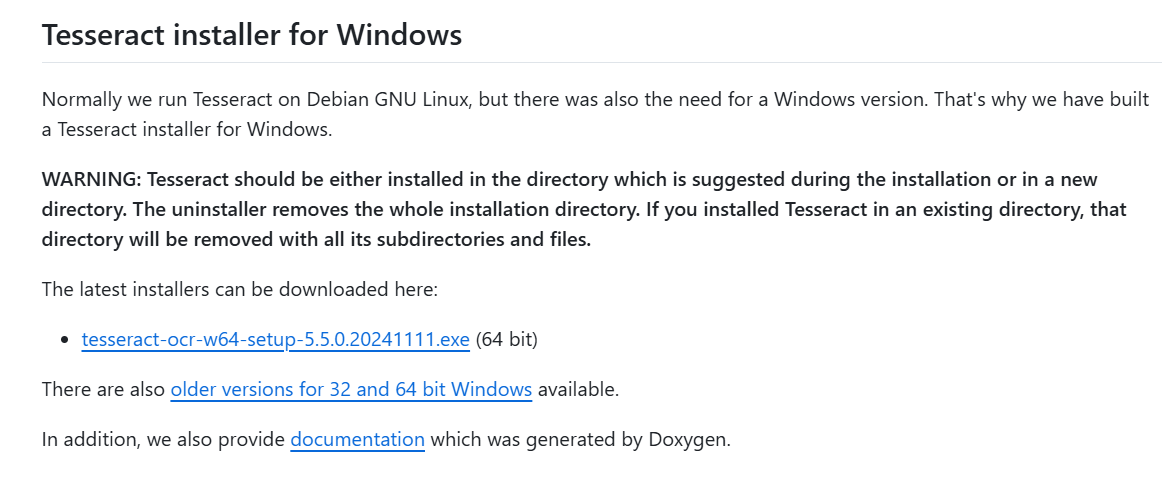
Tesseract介紹Tesseract 是一個(gè)開(kāi)源的光學(xué)字符識(shí)別(OCR)引擎,最初由 HP 在 1985 年至 1995 年間開(kāi)發(fā),后來(lái)被 Google 收購(gòu)并開(kāi)源。Tesseract 支持多種語(yǔ)言的文本識(shí)別,能夠識(shí)別圖片中的文字,并將其轉(zhuǎn)換為可編輯和可搜索的數(shù)據(jù)格式。它適用于多種應(yīng)用場(chǎng)景,包括文檔掃描、圖像處理、數(shù)字存檔等。 Tesseract 的最新版本顯著提高了識(shí)別準(zhǔn)確率,支持的文件格式包括 TIFF、JPEG、PNG 等常見(jiàn)圖片格式。此外,Tesseract 還提供了一個(gè)命令行工具,允許用戶通過(guò)簡(jiǎn)單的命令行輸入來(lái)執(zhí)行 OCR 任務(wù)。對(duì)于開(kāi)發(fā)者而言,Tesseract 提供了多種編程語(yǔ)言的 API 接口,如 C++、Python、Java 等,使得集成 OCR 功能到各種應(yīng)用程序中變得更為容易。 除了基本的 OCR 功能外,Tesseract 還支持語(yǔ)言模型和訓(xùn)練工具,允許用戶根據(jù)特定需求訓(xùn)練自定義模型,以提高某些特定類型或格式文本的識(shí)別準(zhǔn)確率。這些特性使得 Tesseract 成為了一個(gè)強(qiáng)大而靈活的 OCR 工具,廣泛應(yīng)用于個(gè)人和企業(yè)的文本數(shù)字化處理中。 GitHub地址:https://github.com/tesseract-ocr/tesseract 官方文檔地址:https://tesseract-ocr.github.io ? 下載安裝Tesseract下載Tesseract Home · UB-Mannheim/tesseract Wiki
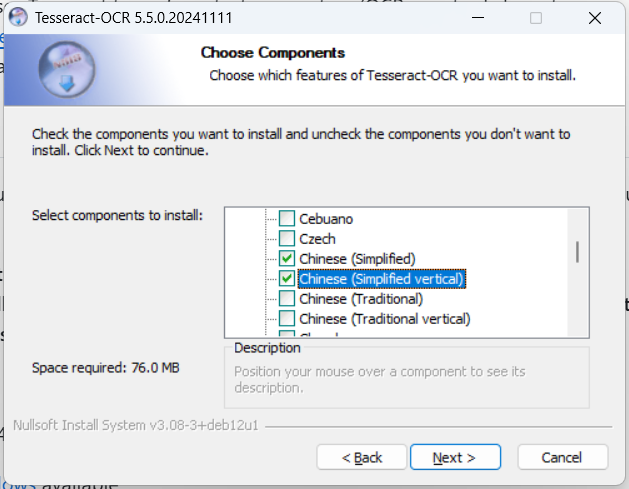
安裝的時(shí)候,記得選上中文語(yǔ)言包:
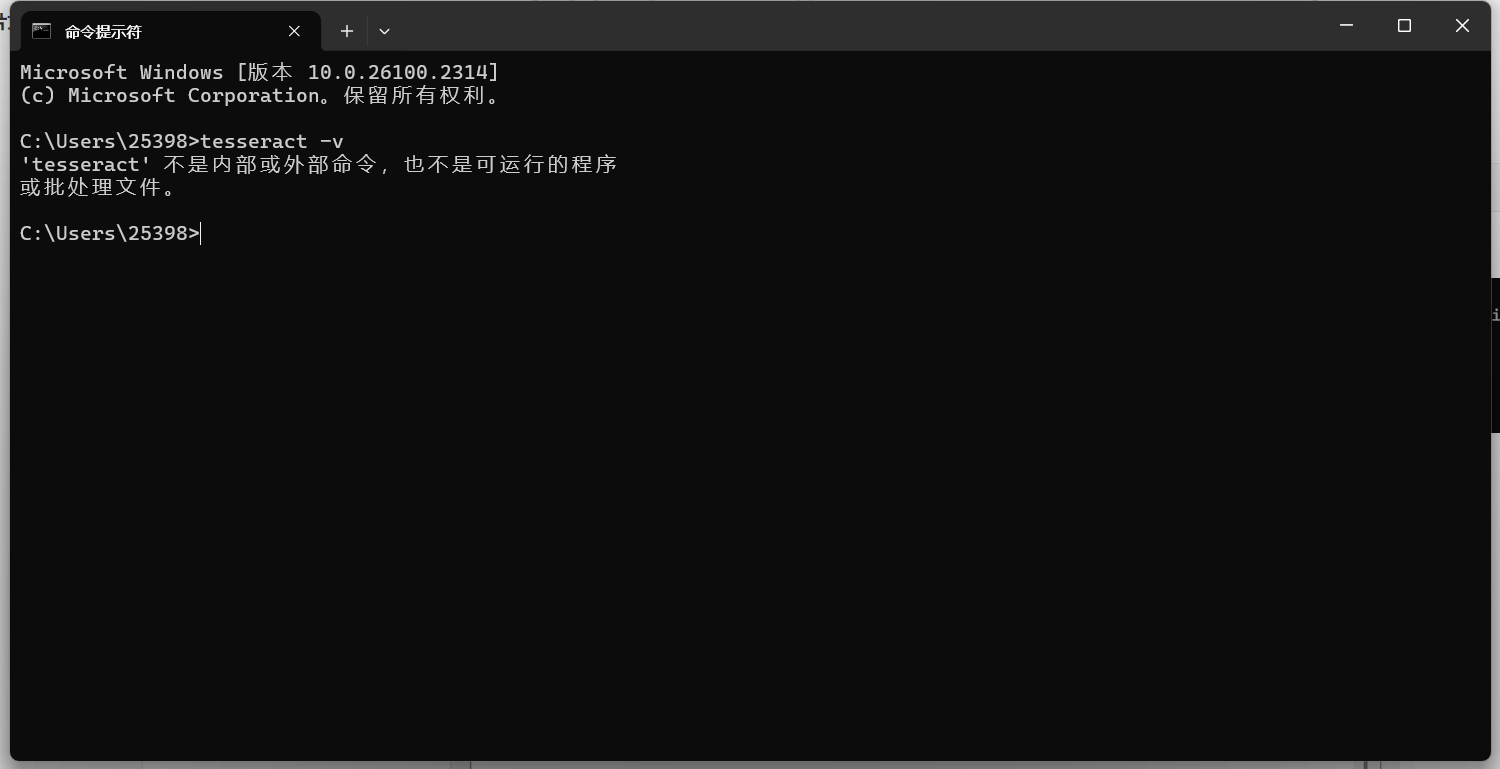
輸入 查看Tesseract是否安裝成功
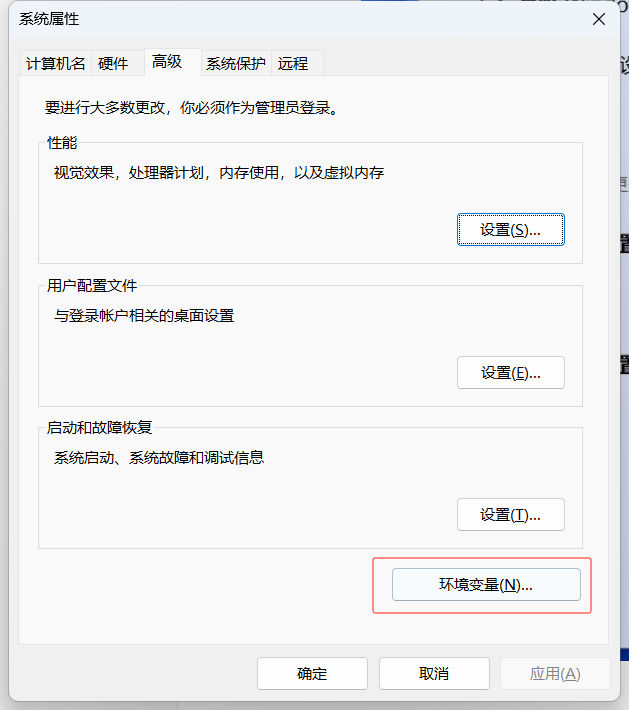
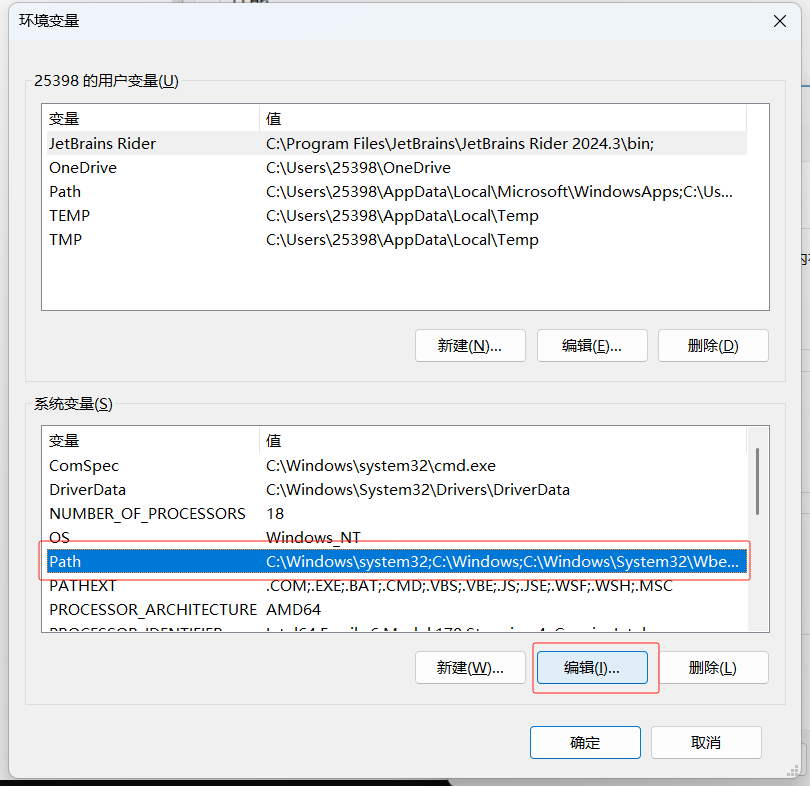
設(shè)置環(huán)境變量:
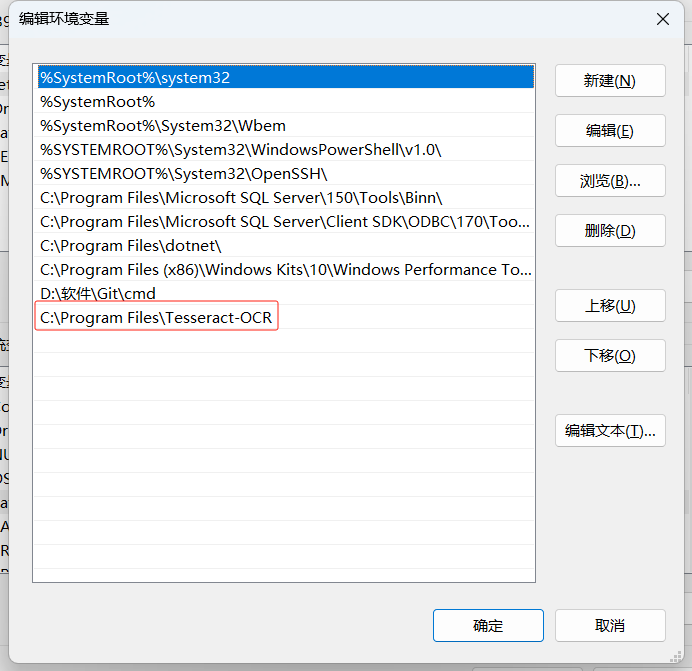
輸入Tesseract的安裝地址:
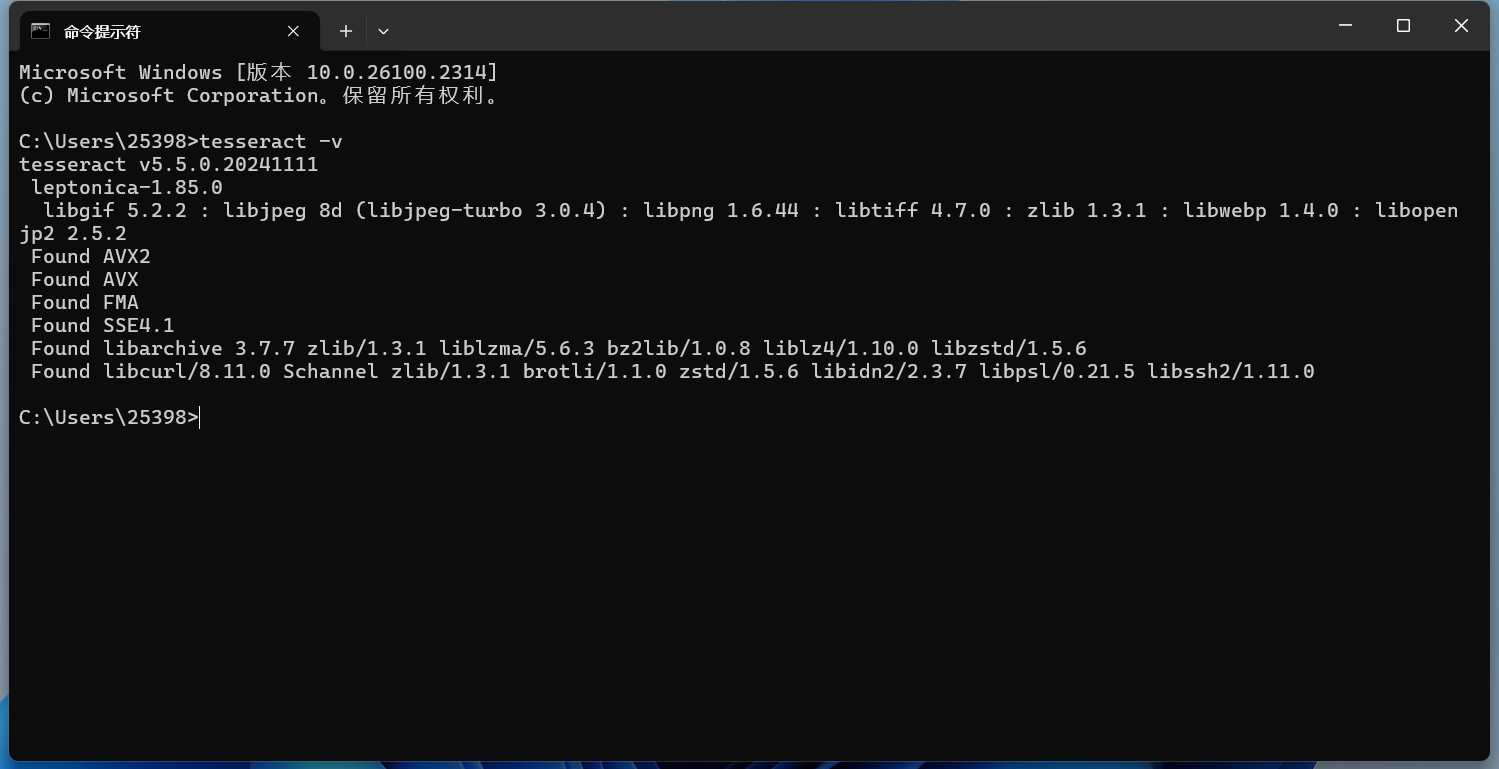
注意安裝路徑最好不要包含中文,由于C盤空間還比較充足,我就裝在默認(rèn)位置了。 再次驗(yàn)證安裝是否完成:
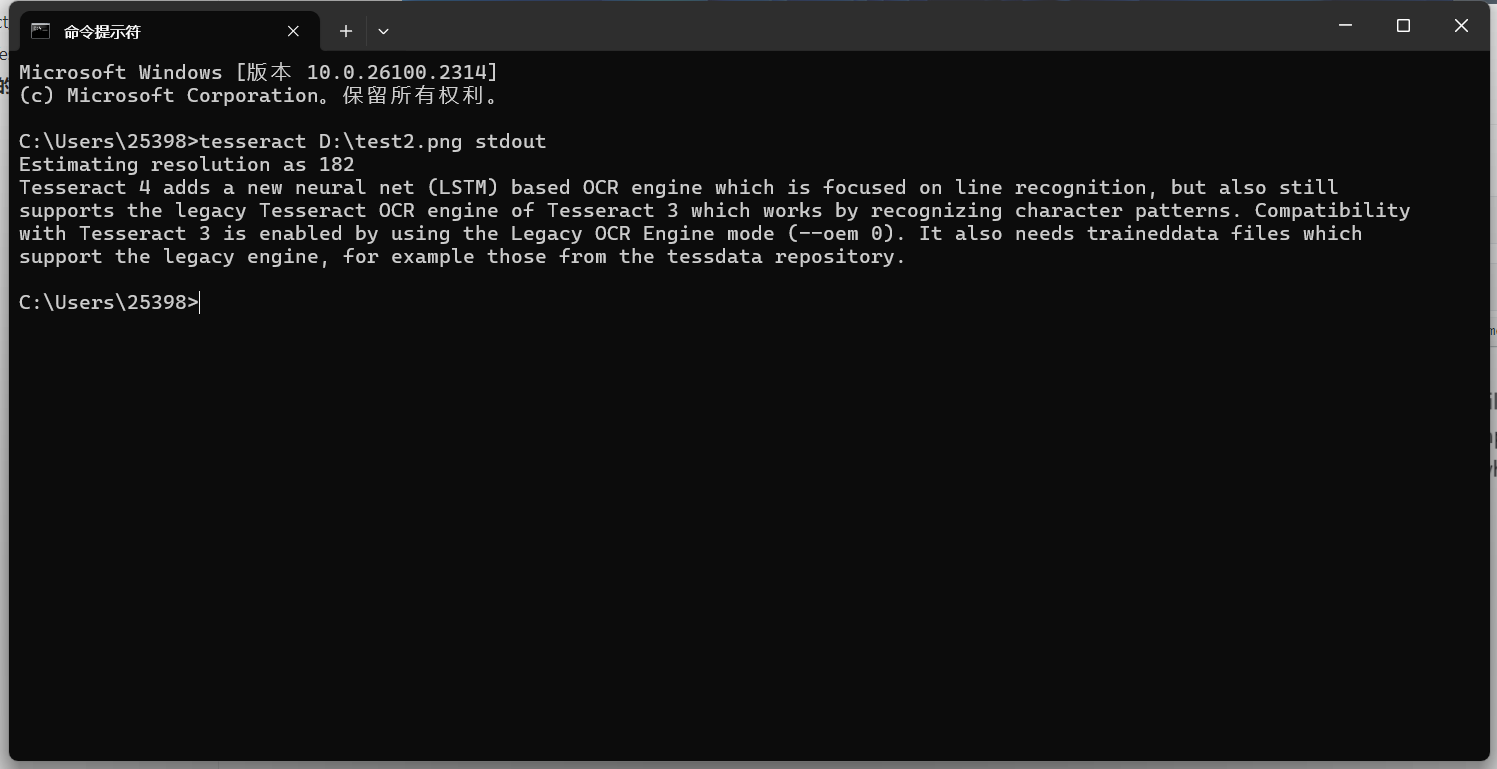
安裝成功完成。 Tesseract的基本命令行使用基本文本識(shí)別最簡(jiǎn)單的命令是將圖片中的文本識(shí)別并輸出到標(biāo)準(zhǔn)輸出(屏幕): 默認(rèn)識(shí)別的是英文的,先拿一個(gè)英文的圖片試試:
圖片文字識(shí)別的效果
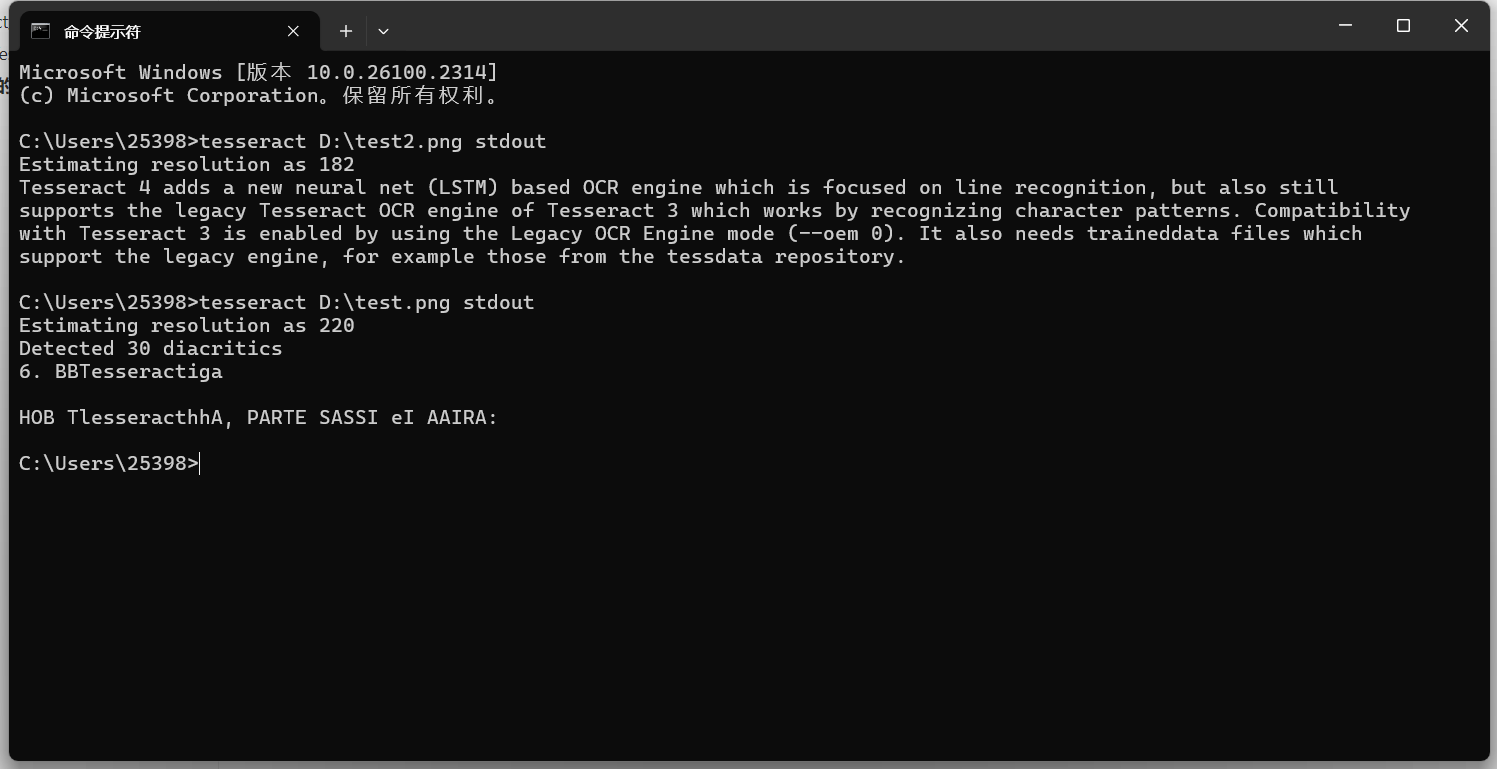
效果還是很ok的。 再試試一個(gè)中文的圖片:
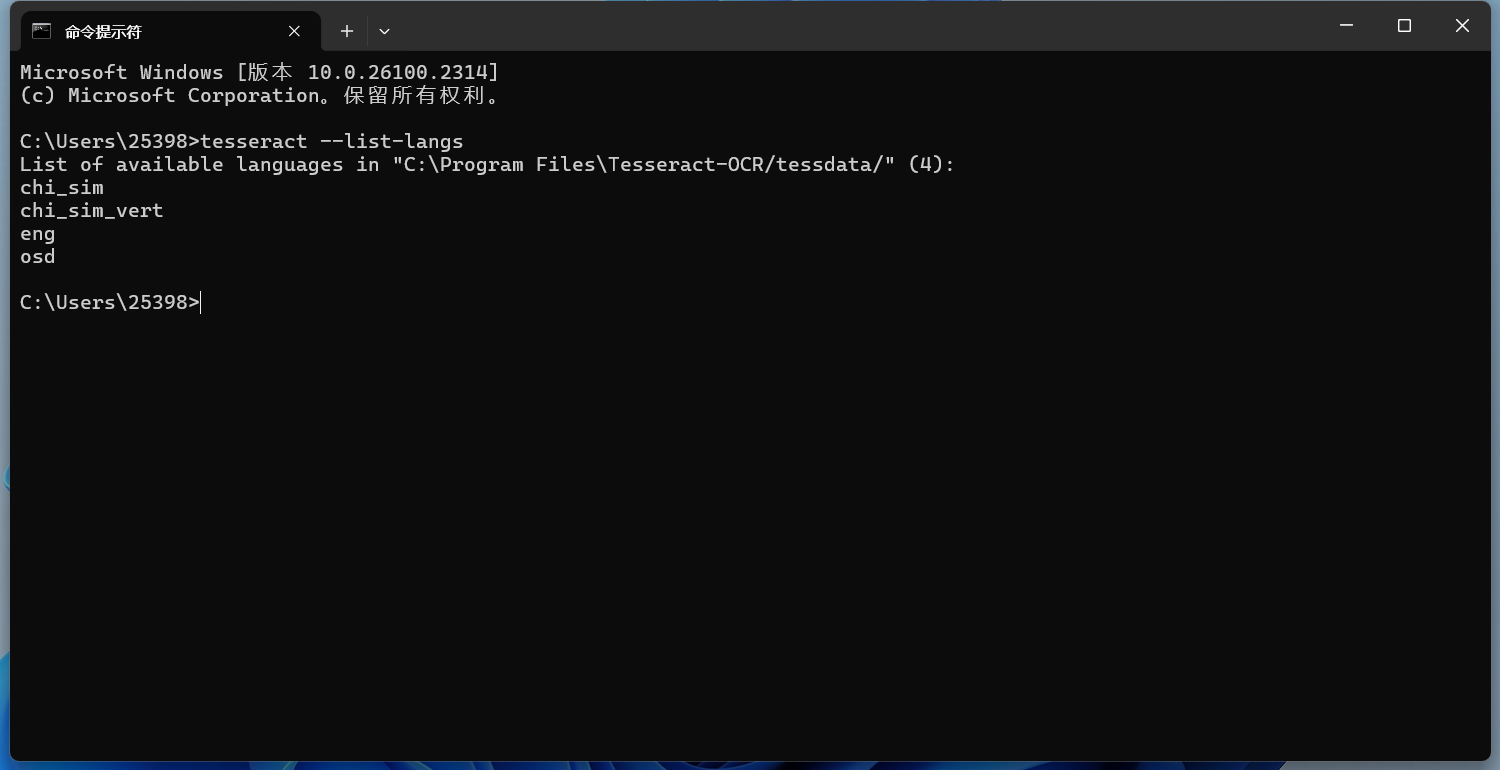
默認(rèn)是無(wú)法識(shí)別中文的,這時(shí)候需要指定語(yǔ)言才行。 指定一種語(yǔ)言識(shí)別如果圖片中的文字不是英文,你需要指定相應(yīng)的語(yǔ)言。Tesseract 支持多種語(yǔ)言,可以通過(guò)以下命令查看支持的語(yǔ)言:
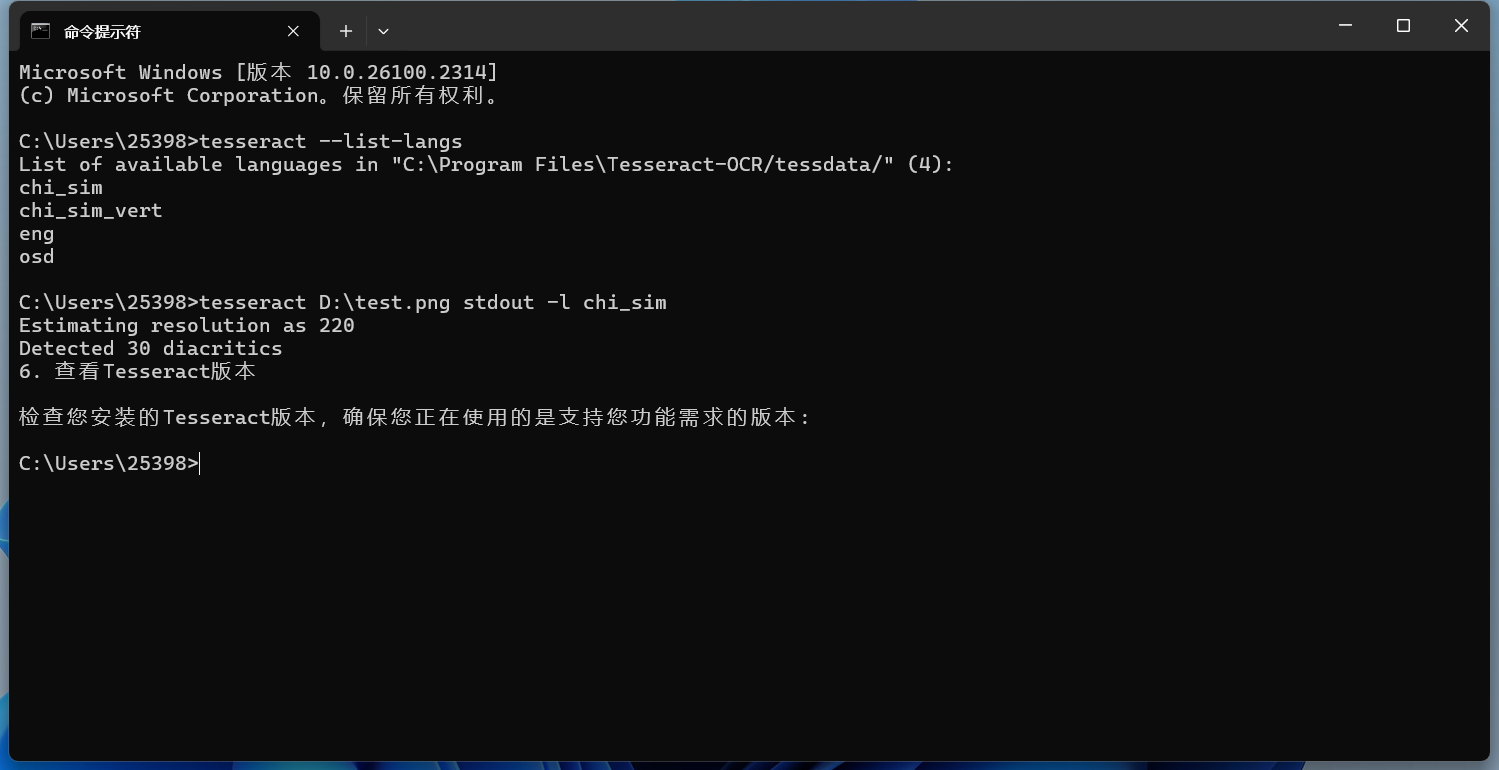
會(huì)出現(xiàn)你已經(jīng)下載了語(yǔ)言包的語(yǔ)言。 指定語(yǔ)言的命令如下(例如,識(shí)別中文): 這里的
效果也很不錯(cuò)。 指定多種語(yǔ)言識(shí)別有時(shí)候我們需要同時(shí)識(shí)別多種語(yǔ)言,以下面這張圖片為例:
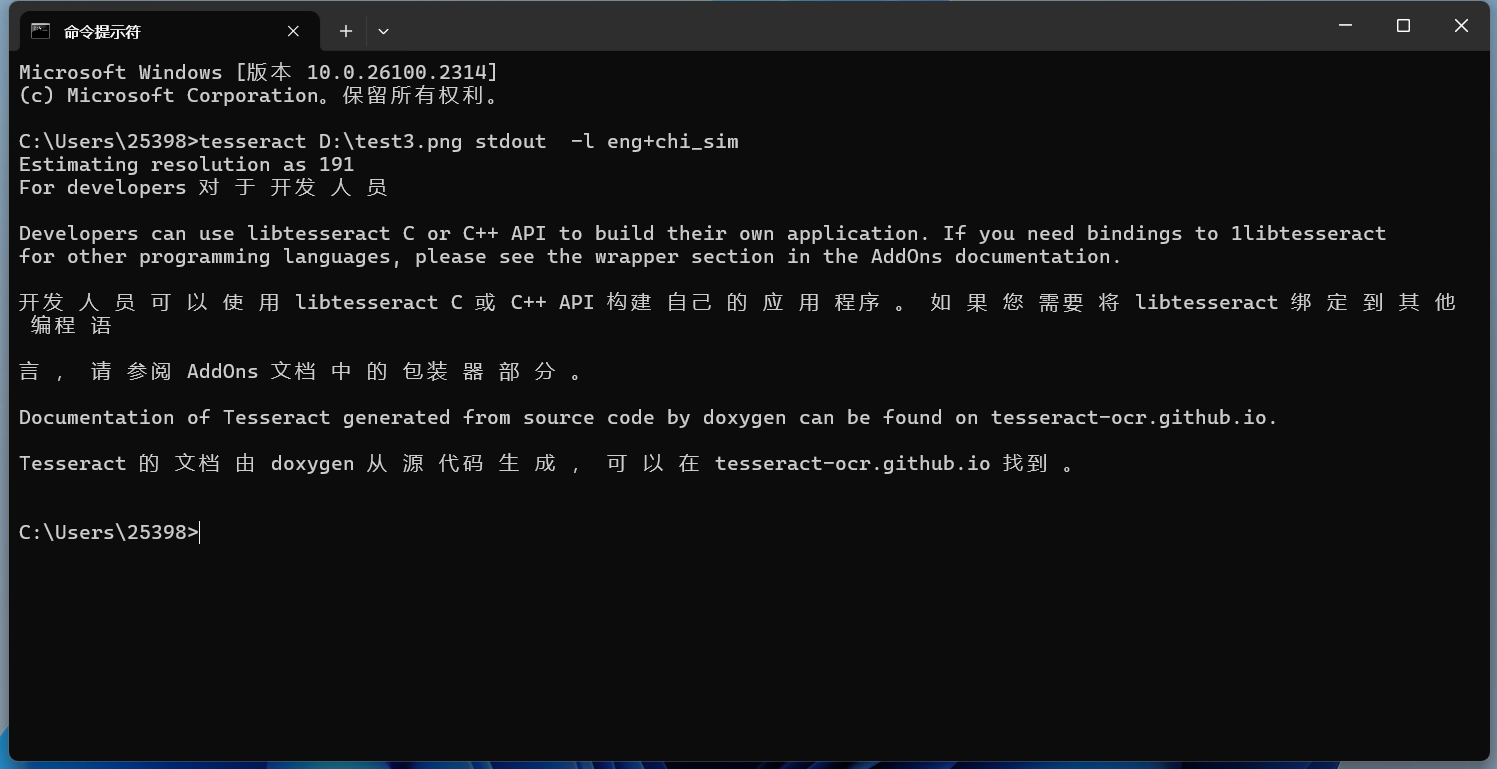
在命令行中添加-l LANG[+LANG]可以使用多種語(yǔ)言進(jìn)行識(shí)別:
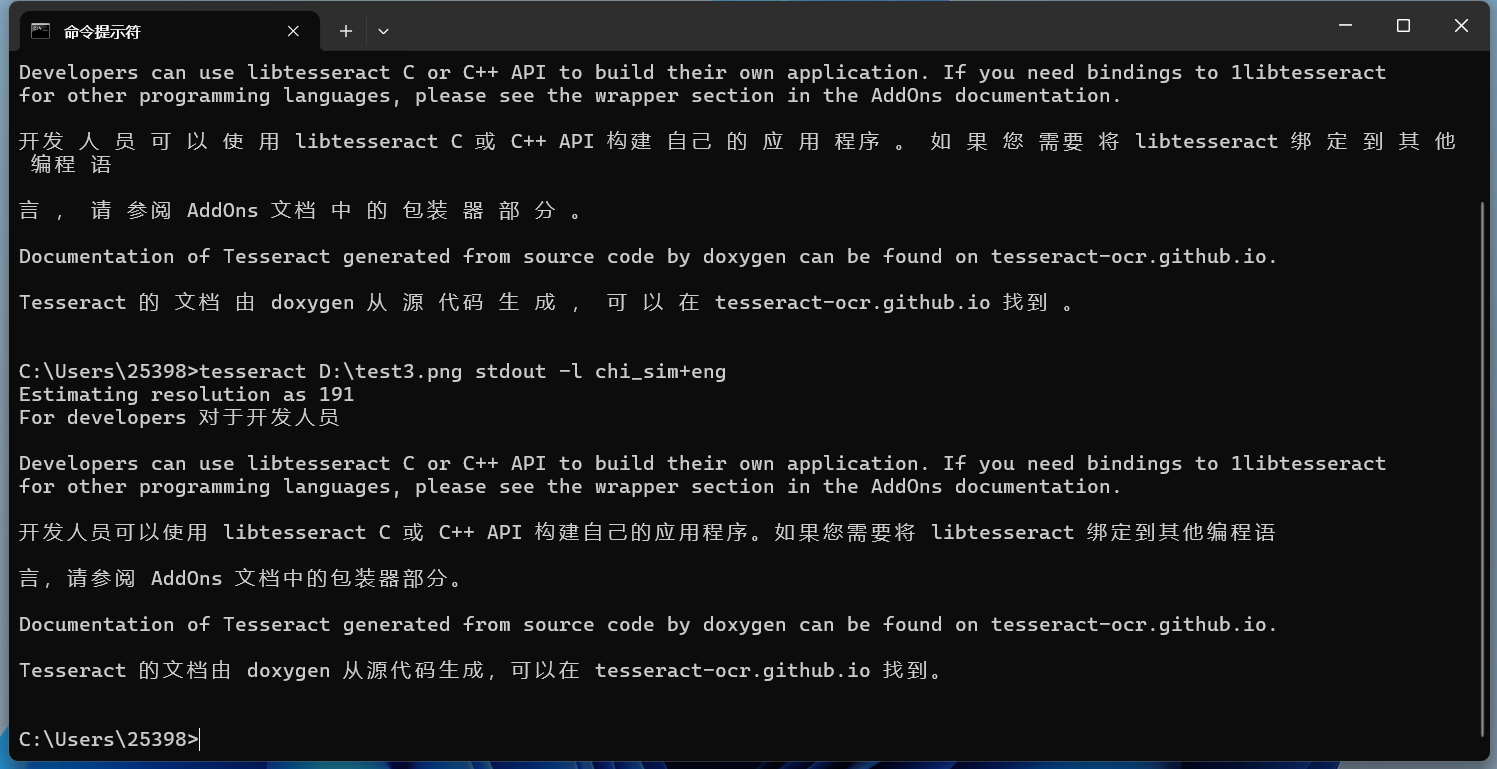
效果也還行。但是會(huì)發(fā)現(xiàn)識(shí)別的中文很多地方都有空格。 將中文改為主要識(shí)別語(yǔ)言:
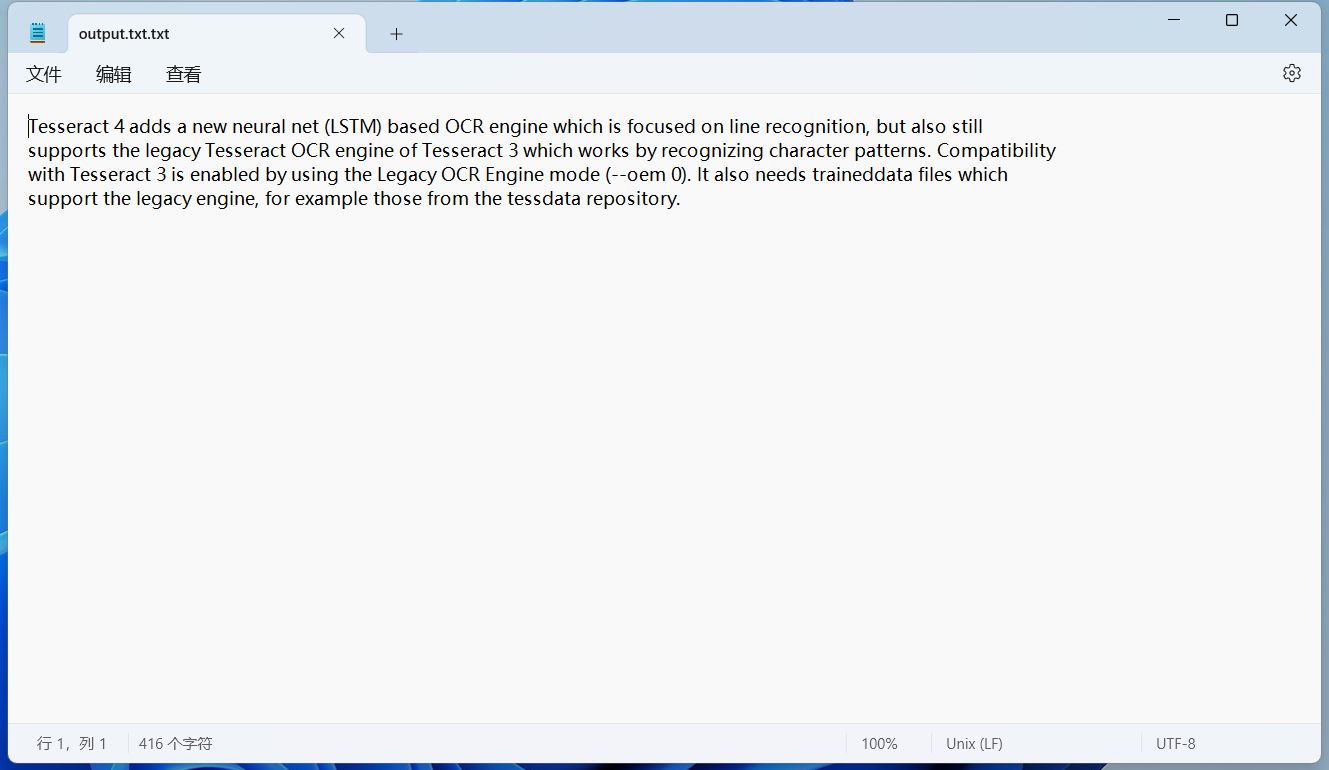
可以發(fā)現(xiàn)識(shí)別的空格少了很多。 保存識(shí)別文本到文件也可以把識(shí)別的內(nèi)容保存在一個(gè)txt文件中,命令如下所示:
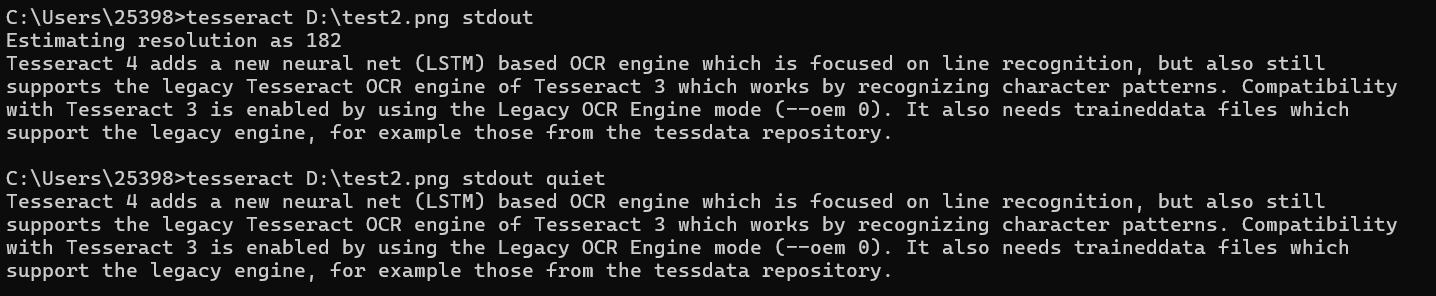
使用quiet模式抑制消息不使用quiet模式與使用quiet模式的對(duì)比:
少了表示 Tesseract 正在嘗試估算輸入圖像的分辨率的信息 可搜索的pdf輸出這將創(chuàng)建一個(gè)包含圖像和單獨(dú)可搜索文本層的PDF,其中包含識(shí)別出的文本: 實(shí)現(xiàn)效果:
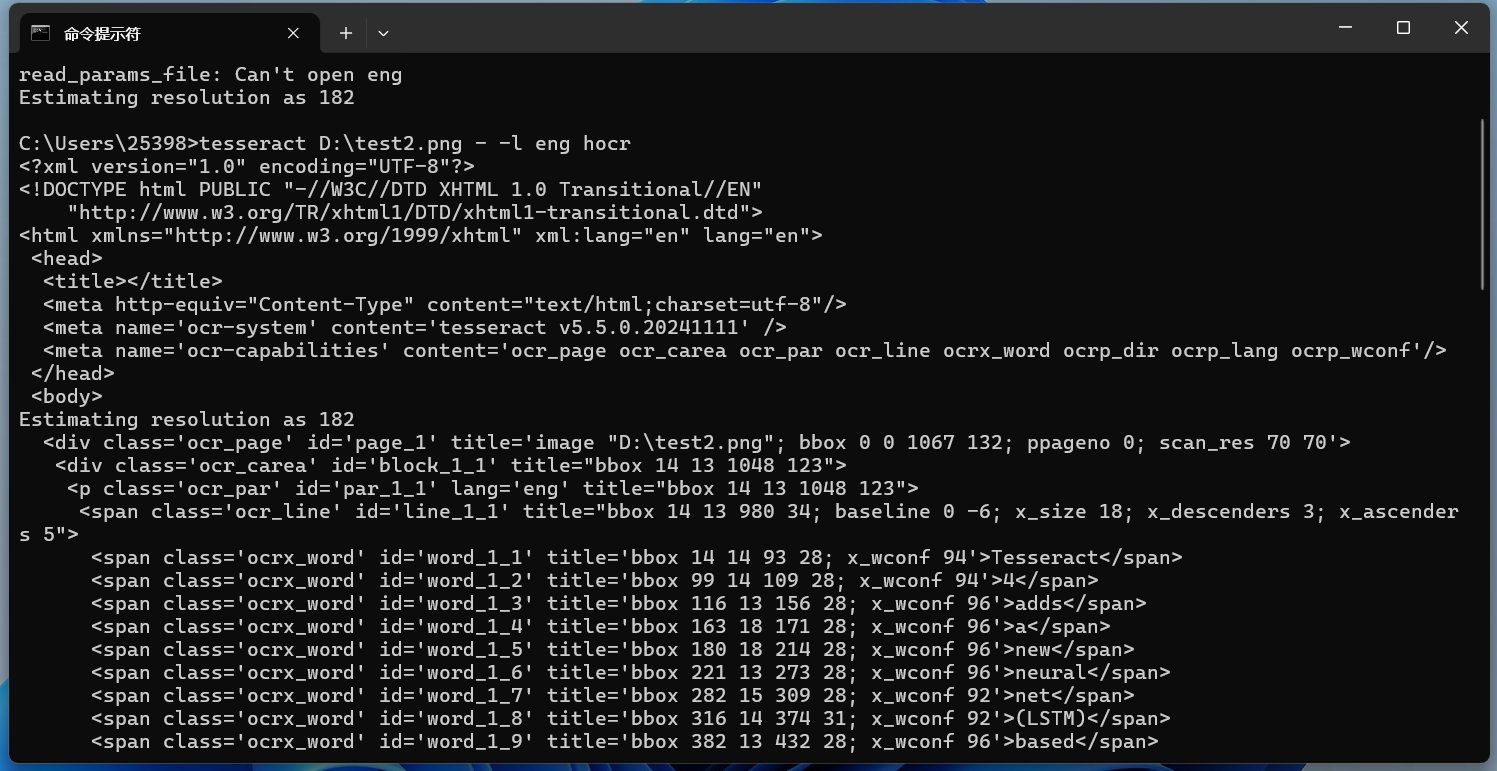
HOCR輸出在命令末尾添加hocr以使用‘hocr’配置文件,獲取HOCR輸出: 識(shí)別效果:
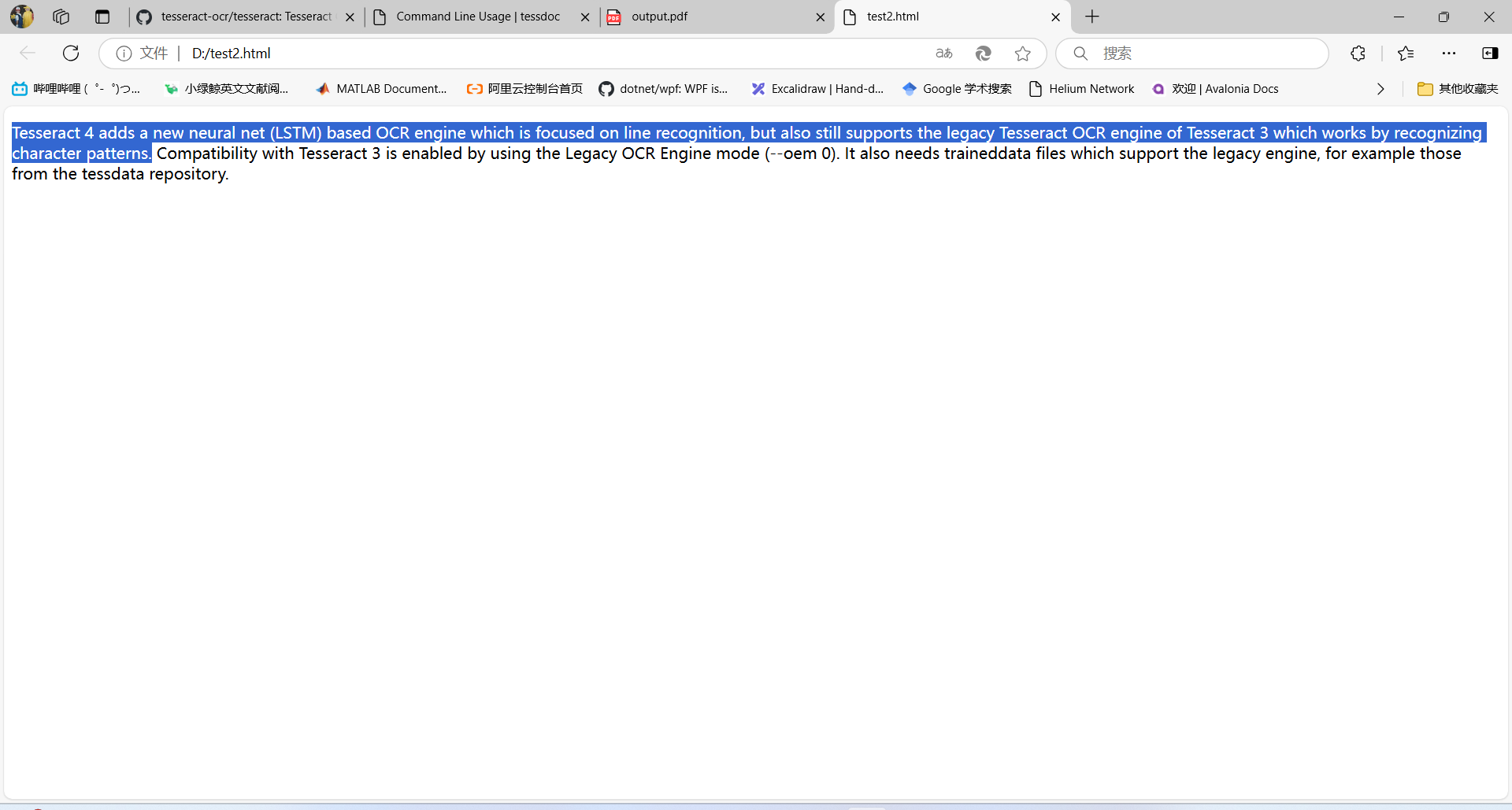
這樣不夠直觀,保存在一個(gè)html文件中,然后再打開(kāi)看看: 把生成的文件后綴改為.html,用瀏覽器打開(kāi),效果如下所示:
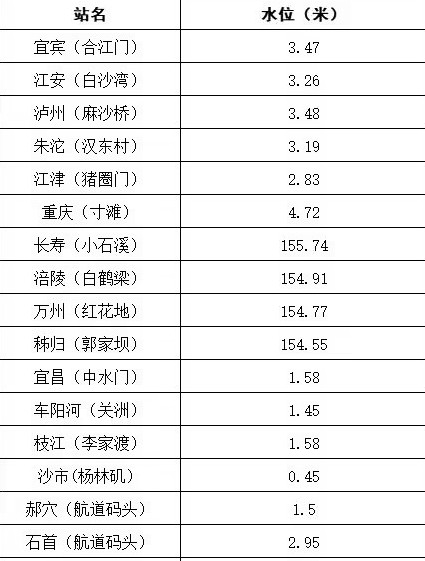
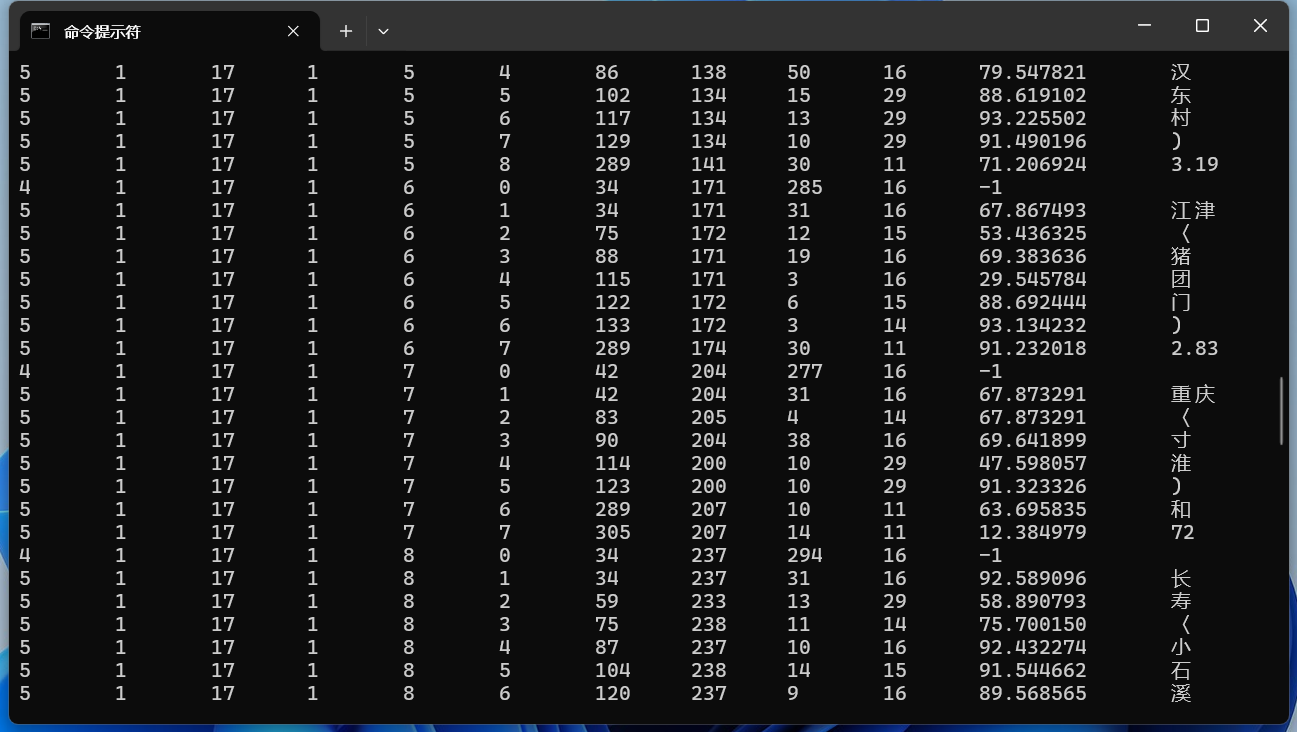
TSV輸出在命令末尾添加“tsv”配置文件以獲取TSV輸出: 以這張圖片為例:
實(shí)現(xiàn)效果如下所示:
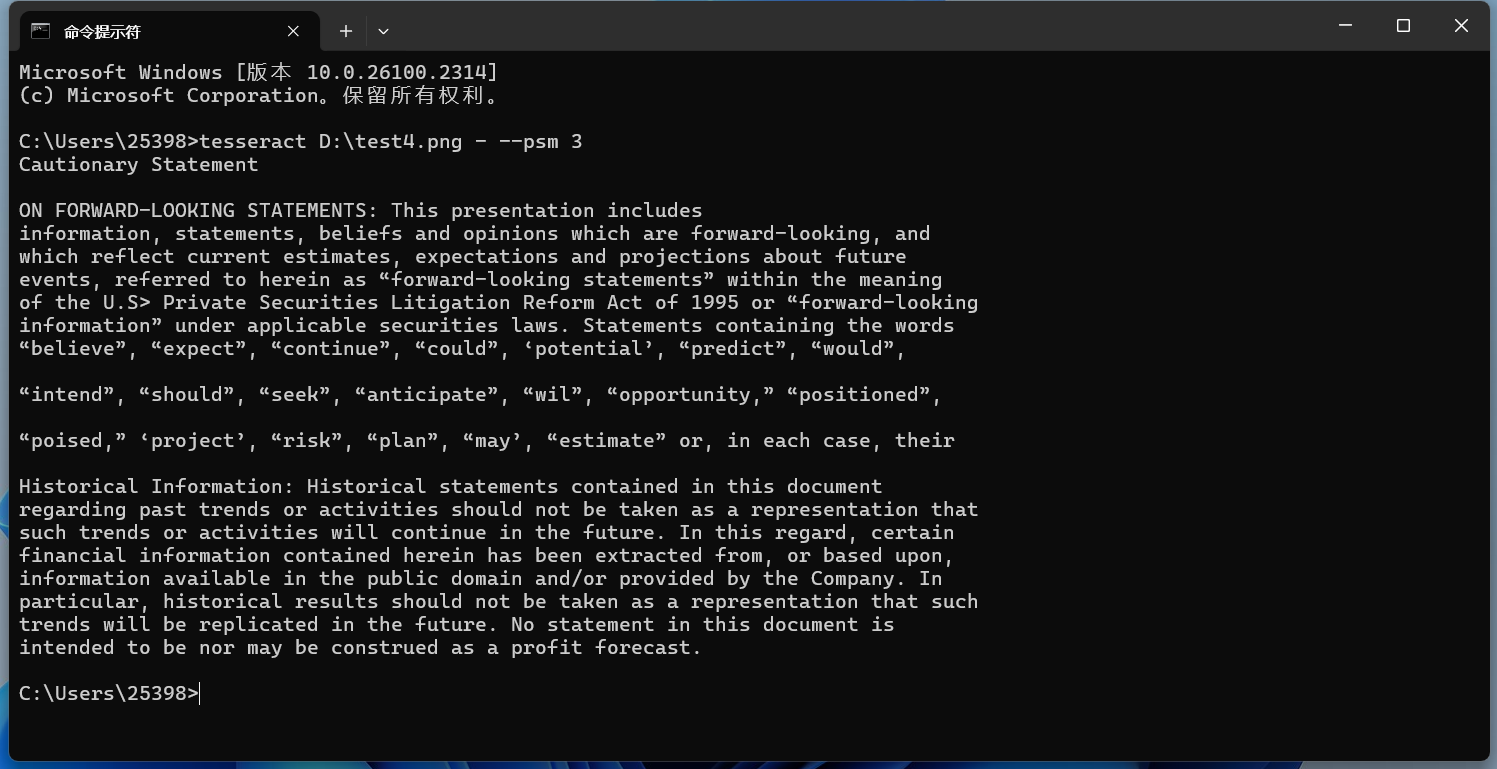
使用不同的頁(yè)面分割模式-psm 3 - 全自動(dòng)頁(yè)面分割,但無(wú)方向和腳本檢測(cè)。(默認(rèn)) 以這張圖片為例:
實(shí)現(xiàn)的效果:
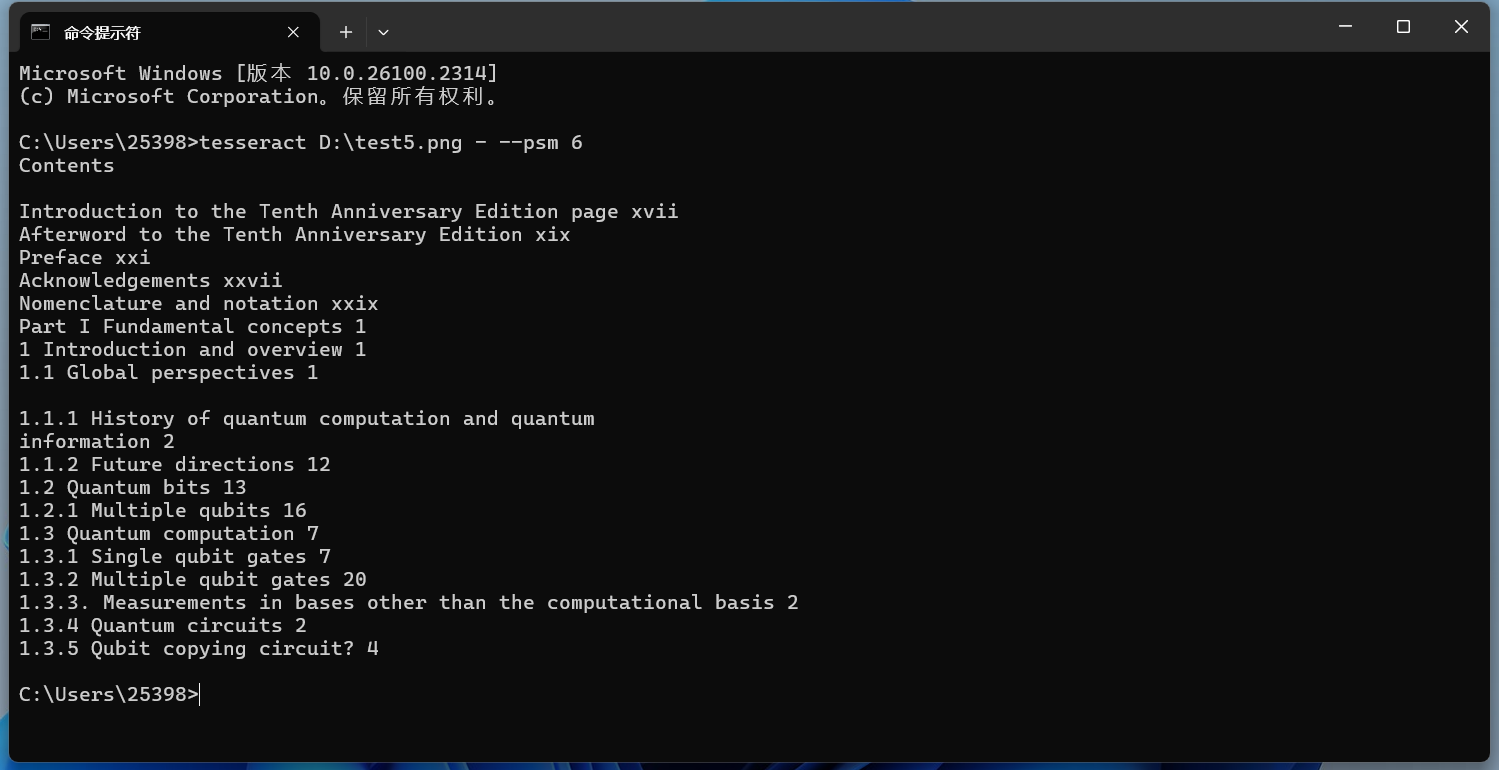
-psm 6 - 假定文本為一個(gè)整體均勻的塊。 以這張圖片為例:
實(shí)現(xiàn)效果如下所示:
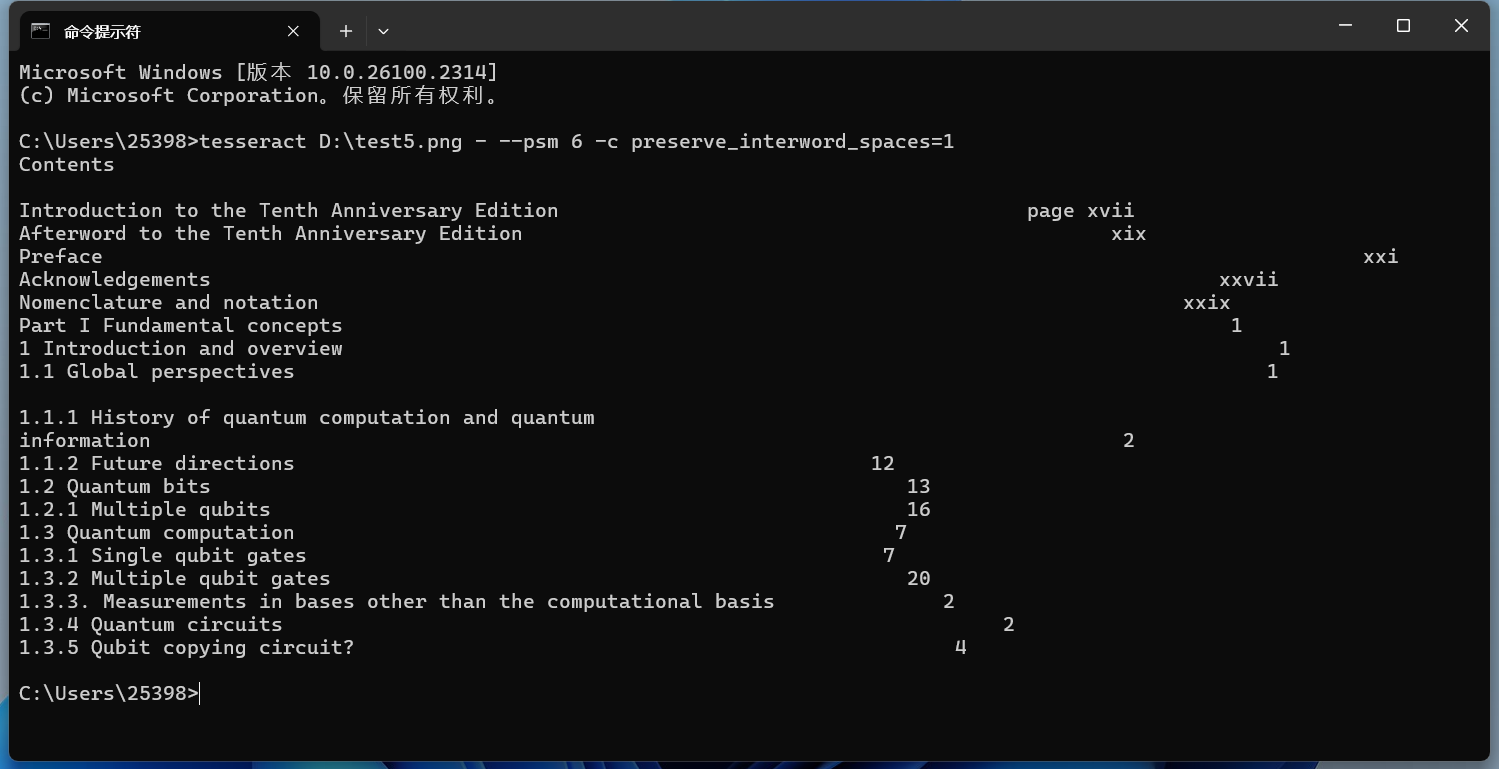
使用 -c preserve_interword_spaces=1 來(lái)保留空格 實(shí)現(xiàn)效果如下所示:
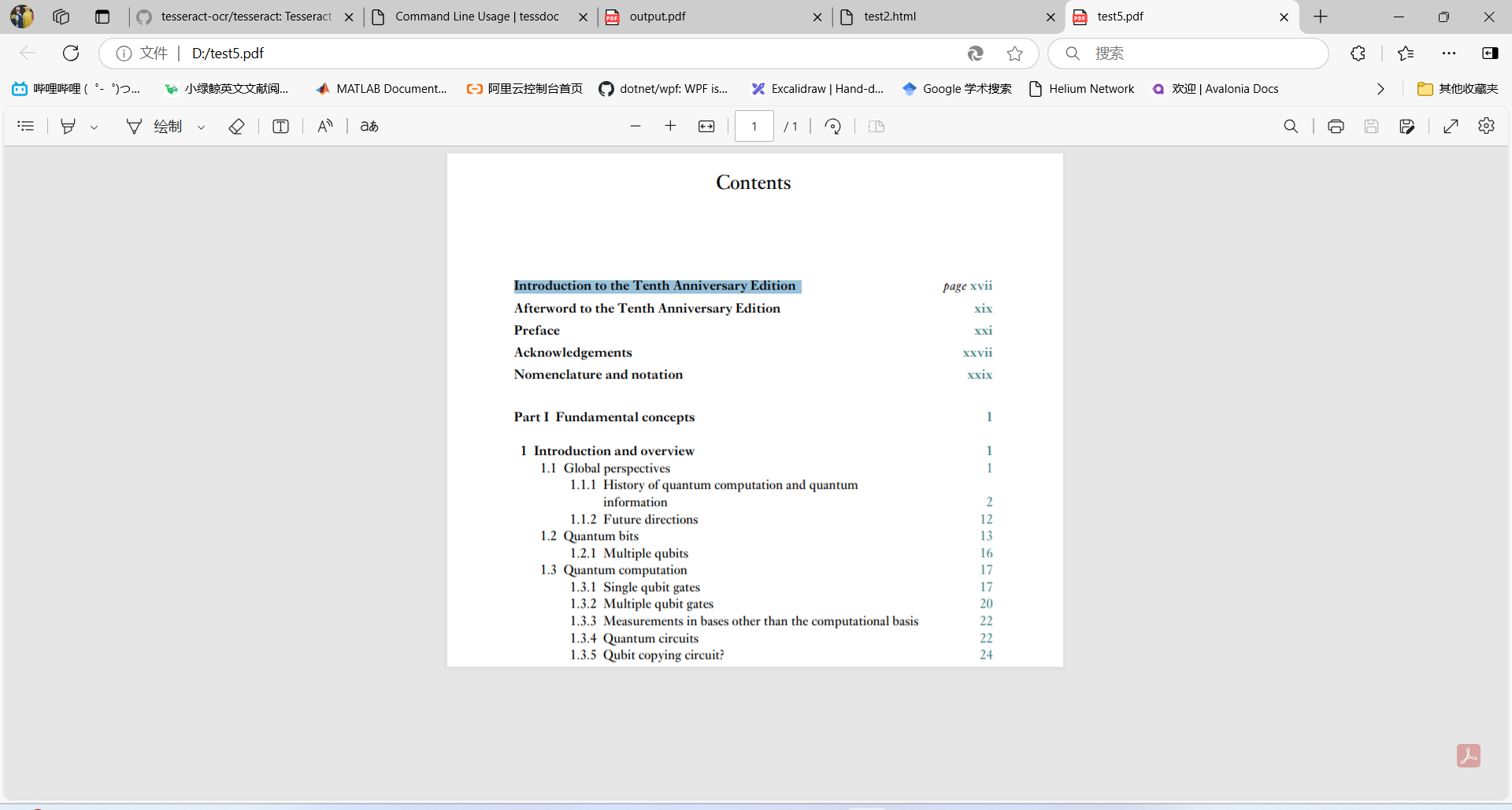
使用pdftotext保持文本輸出的布局 實(shí)現(xiàn)的效果:
總結(jié)現(xiàn)在圖片文字識(shí)別已經(jīng)有多種方式可以實(shí)現(xiàn),也可以通過(guò)云服務(wù)商的文字識(shí)別服務(wù),缺點(diǎn)就是需要網(wǎng)絡(luò),數(shù)量多了需要收費(fèi),優(yōu)點(diǎn)就是識(shí)別準(zhǔn)確率比較高。使用Tesseract與PaddleOCR這種方式的好處就是離線可用,速度也挺快的。 轉(zhuǎn)自https://www.cnblogs.com/mingupupu/p/18590261 該文章在 2024/12/9 9:42:01 編輯過(guò) |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")